
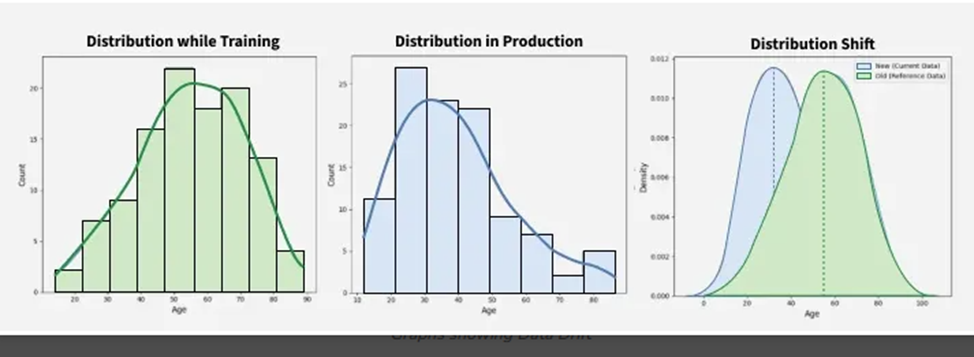
Дрейф данных (Drift Data) — это ситуация, когда статистические свойства входных данных для модели машинного обучения изменяются со временем. При дрейфе данных взаимосвязи между признаками и самой целевой переменной перестают быть действительными. Это может привести к низкой производительности модели, неточным прогнозам и даже к сбоям.
Почему происходит дрейф моделей — причины дрейфа данных и устаревание данных
Модели машинного обучения могут испытывать дрейф с течением времени по нескольким причинам. Одна из наиболее распространенных причин — устаревание данных, используемых для обучения модели, или их несоответствие текущим условиям. Другая причина дрейфа заключается в том, что некоторые модели не предназначены для адаптации к изменениям данных. Хотя некоторые модели лучше приспособлены для обработки этих изменений, ни одна модель не застрахована от дрейфа.
Например, предположим, что модель машинного обучения предназначена для прогнозирования цены акций компании с использованием исторических данных. Если она обучена на данных со стабильного рынка, она может показать хорошие результаты на начальном этапе. Однако, если рынок станет более волатильным, модель может начать испытывать трудности с точностью прогнозов, поскольку статистические характеристики данных изменятся.
Типы дрейфа данных и их влияние на модели (концептуальный, ковариатный, сезонный)
Дрейф концепции (Concept Drift) — изменение связи между признаками (X) и целевой переменной (Y)
Дрейф концепции относится к изменению статистической связи между входными признаками (X) и целевой переменной (Y) с течением времени. Это означает, что закономерности, изученные моделью машинного обучения в определенный момент, могут перестать быть актуальными в будущем, что влияет на производительность модели и ее способность к обобщению.
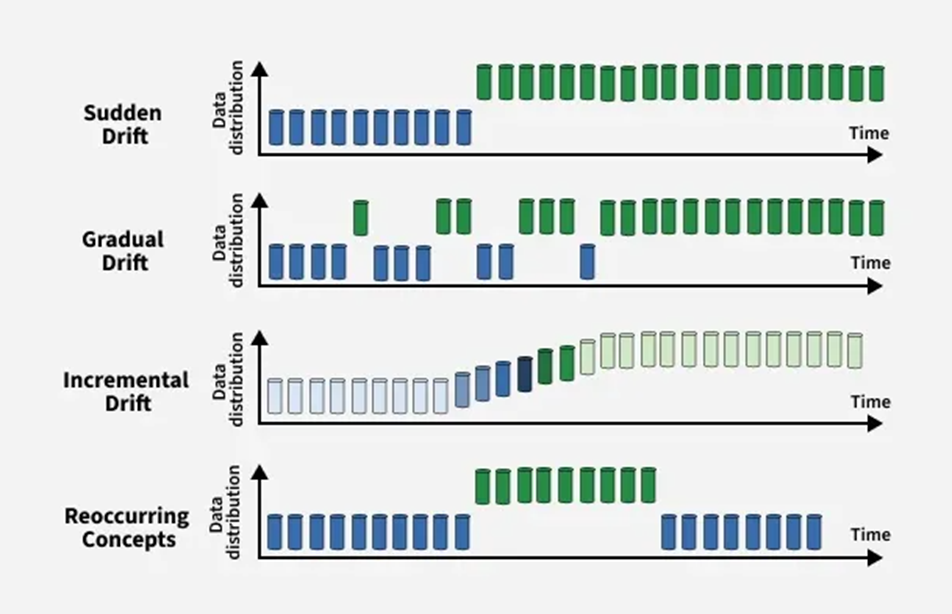
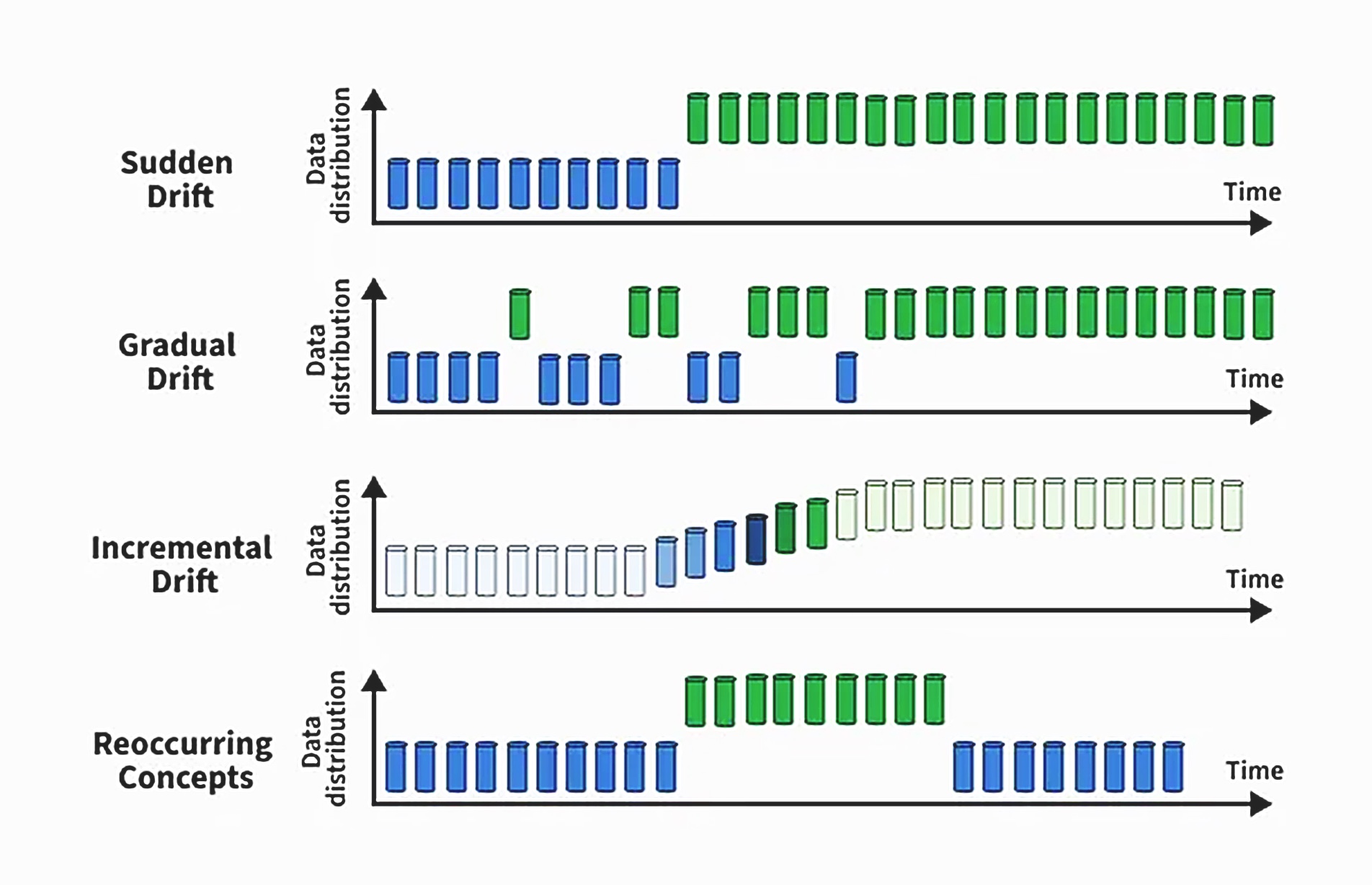
Внезапный дрейф (sudden drift)
Внезапный дрейф: быстрое изменение распределения данных, при котором новая концепция полностью заменяет старую. Это часто приводит к немедленному снижению точности модели, если не принять соответствующие меры.
Постепенный дрейф (gradual drift)
Постепенный дрейф: распределение данных изменяется медленно с течением времени, позволяя старым и новым концепциям сосуществовать некоторое время. Модель может по-прежнему показывать достаточно хорошие результаты во время этого перехода, но производительность снижается, если адаптация задерживается.
Инкрементальный дрейф (incremental drift)
Инкрементальный дрейф: изменение концепции происходит посредством последовательности небольших шагов. Каждый шаг вносит небольшое отклонение, в конечном итоге приводя к существенно другой концепции. Этот тип дрейфа может быть незаметным и трудно обнаружим.
Повторяющийся или сезонный дрейф (recurring/seasonal drift)
Повторяющийся или сезонный дрейф: ранее наблюдаемые концепции появляются снова через определенный период. Например, сезонные закономерности в розничных продажах или циклическое поведение пользователей могут привести к повторному появлению определенных распределений данных, что требует от моделей сохранения памяти о прошлых состояниях.
Дрейф ковариат (Covariate Drift) — изменение распределения признаков X
Дрейф ковариат происходит, когда распределение входных признаков изменяется со временем, в то время как условная связь между входными данными (X) и целевым выходом (Y) остается неизменной. Проще говоря, изменяется способ распределения входных данных, но базовое отображение от X к Y остается неизменным. Это все еще может повлиять на производительность модели, если модель подвергается воздействию входных шаблонов, с которыми она не сталкивалась во время обучения.
Алгоритмы и методы для обнаружения дрейфа данных (статистические тесты и детекторы)
Критерий Колмогорова—Смирнова (K-S) — тест для обнаружения изменения распределения
Критерий Колмогорова—Смирнова (К–С) — это статистический тест, используемый для определения того, происходят ли два набора данных из одного и того же распределения. Он не предполагает конкретной формы распределения, что делает его подходящим для широкого спектра приложений. Этот метод часто применяется при проверке, взята ли выборка данных из определенной популяции, или при сравнении двух выборок для оценки принадлежности к одному распределению.
Механизм: тест сравнивает кумулятивные функции распределения (КФР) двух наборов данных и измеряет максимальную разницу между ними. По умолчанию тест предполагает, что оба набора данных принадлежат к одному и тому же распределению. Если это предположение отклоняется, это указывает на разницу в распределениях и, возможно, на дрейф данных.
Индекс стабильности популяции (PSI) — метрика изменения распределения признаков
Индекс стабильности популяции (PSI) — это статистический показатель, используемый для оценки того, насколько изменилось распределение переменной между двумя наборами данных. Он широко применяется для отслеживания изменений категориальных или непрерывных переменных с интервалами во времени. Хотя первоначально PSI разрабатывался для мониторинга стабильности кредитных рейтингов, он часто используется в пайплайнах машинного обучения.
PSI сравнивает долю наблюдений в каждом интервале распределения переменной в обучающем наборе и в текущем (входящем или тестовом) наборе данных. Разница в этих долях по всем интервалам суммируется в единый показатель PSI.
Интерпретация PSI:
PSI < 0,1: отсутствие значительных изменений в распределении.
0,1 ≤ PSI < 0,25: умеренные изменения, требуется более тщательный мониторинг.
PSI ≥ 0,25: значительный дрейф, вероятно, потребуется переобучение или перекалибровка модели.
Метод Пейджа—Хинкли (Page-Hinkley) — последовательное обнаружение изменений в средних
Метод Пейджа—Хинкли — это последовательный метод обнаружения изменения среднего значения потока данных во времени. Он применяется для мониторинга временных рядов или потоковых данных, где раннее обнаружение изменений критично. Часто используется для мониторинга производительности модели и обнаружения сдвигов, неочевидных на первый взгляд.
Подход: задается пороговое значение и функция принятия решения. Затем вычисляется кумулятивная разница между наблюдаемыми значениями и их скользящим средним. Если накопленная разница превышает порог, фиксируется изменение среднего (дрейф).
Реализация обнаружения дрейфа данных в Python — пример с K-S тестом
Далее приведен пример реализации K-S теста и визуализации распределений в Python. Пример использует синтетические данные: базовая выборка со средним 0 и входящая выборка со средним 2, что моделирует дрейф распределения вправо.
1. Импорт библиотек
import numpy as np
import pandas as pd
from scipy.stats import ks_2samp
import matplotlib.pyplot as plt
import seaborn as sns2. Генерация синтетических данных
np.random.seed(42)
baseline_data = np.random.normal(loc=0.0, scale=1.0, size=1000)
new_data = np.random.normal(loc=2.0, scale=1.0, size=1000)3. Визуализация распределения (KDE)
plt.figure(figsize=(10, 5))
sns.kdeplot(baseline_data, label='Базовые данные (N(0,1))', linewidth=2)
sns.kdeplot(new_data, label='Новые данные (N(2,1))', linewidth=2)
plt.title("Распределение базовых и новых данных")
plt.xlabel("Значение признака")
plt.ylabel("Плотность")
plt.legend()
plt.tight_layout()
plt.show()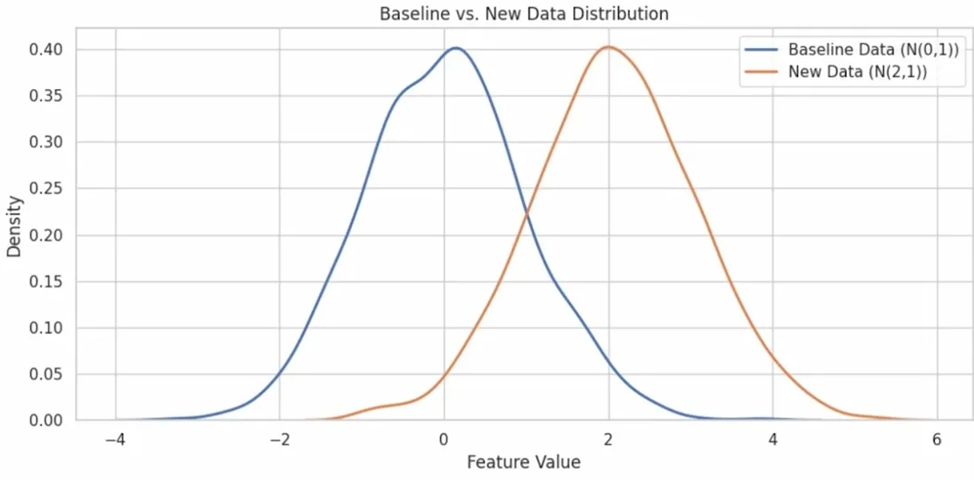
4. Тест Колмогорова—Смирнова (K-S)
ks_statistic, ks_pvalue = ks_2samp(baseline_data, new_data)
print("Kolmogorov-Smirnov Test Result:")
print(f"Statistic: {ks_statistic:.4f}")
print(f"P-value : {ks_pvalue:.4f}")
if ks_pvalue < 0.05:
print("Drift Detected (p < 0.05)")
else:
print("No Significant Drift Detected")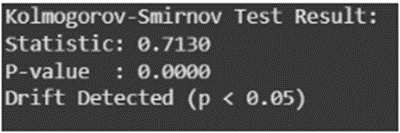
Вывод:
Результат K-S теста показывает наличие дрейфа данных, если p-значение ниже заданного уровня значимости (например, 0.05). Статистика отражает максимальную разницу между двумя кумулятивными функциями распределения; p-значение — вероятность того, что такое различие возникло случайно при нулевой гипотезе об одинаковости распределений.
Управление дрейфом данных — стратегии для стабилизации модели
После обнаружения дрейфа данных важно принять меры для обеспечения точности и надежности модели. Существует несколько эффективных методов управления дрейфом данных:
Переобучение модели: Переобучение позволяет модели изучить новые закономерности и взаимосвязи, которые могли развиться со временем. Эта стратегия подходит, когда имеется достаточное количество размеченных данных и вычислительные ресурсы позволяют провести полное переобучение.
Обновление модели с использованием новых данных: Когда полное переобучение нецелесообразно, модель можно адаптировать постепенно, подстраивая веса или с помощью трансферного обучения. Такой подход удобен для систем реального времени и при ограниченных ресурсах.
Корректировка признаков: Дрейф данных может снизить релевантность некоторых признаков, поэтому инженерия признаков критична. Вводите новые, более информативные признаки и удаляйте нерелевантные, чтобы входы модели лучше отражали текущие тенденции.
Ансамблевое обучение: Использование ансамблей моделей, обученных на разных временных периодах, помогает снизить влияние дрейфа. Методы вроде бэггинга, бустинга или стекинга объединяют прогнозы разных моделей, повышая устойчивость к изменению данных.

Дальнейшие шаги: помимо уметь обнаруживать дрейф, важно встроить мониторинг и автоматическое обновление модели в production-контур. Это включает валидацию входов, непрерывный мониторинг метрик и автоматические пайплайны переобучения при достижении порогов дрейфа.
В заключение: мониторинг дрейфа данных и своевременные меры по обновлению моделей — ключ к поддержанию их производительности в продакшене. Комбинация статистических тестов, визуализации и автоматизированных пайплайнов позволит оперативно реагировать на изменения распределений и минимизировать негативное влияние дрейфа.
Комментарии (0)
Войдите или зарегистрируйтесь, чтобы оставить комментарий
Загрузка комментариев…