
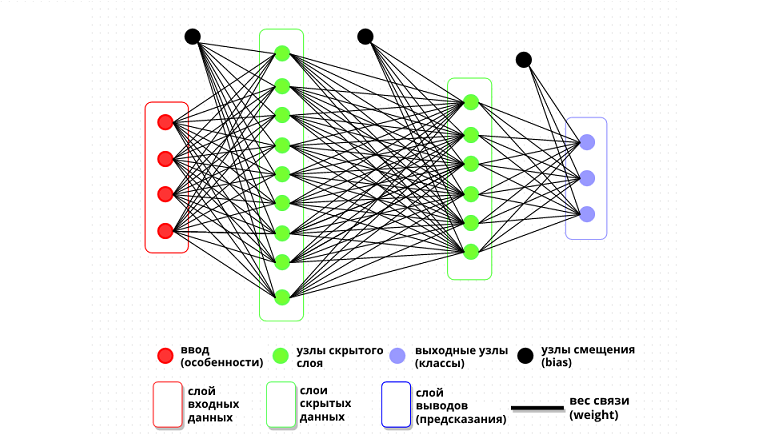
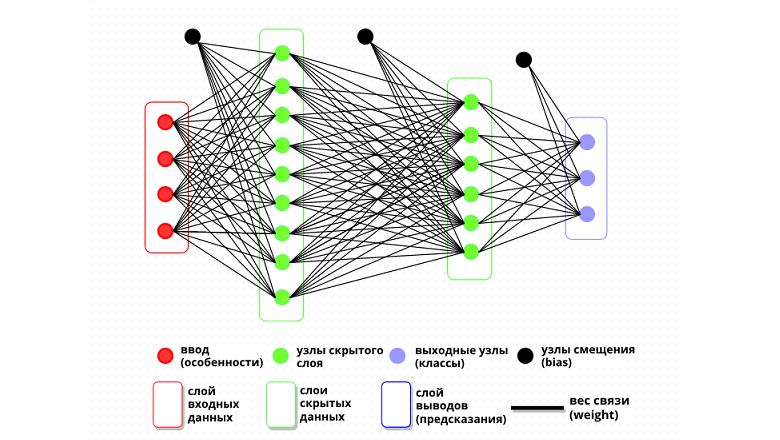
Full-mesh Deep Neural Network (DNN) - Полносвязная Глубокая Нейросеть
Введение: нейросеть, инициализация весов и простая аналогия (ключевые слова: нейросеть, инициализация)
В сети можно найти множество примеров кода нейронных сетей, но зачастую авторы используют библиотеки и «математические приёмчики», не вдаваясь в подробности. Получается «работает — и уже хорошо», главное — уложиться в N строчек кода и объяснить всё за M минут.
Я не утверждаю, что нейросети — элементарная тема, но постараюсь максимально упростить объяснение, сохранив информативность.
Термин «нейрон» заимствован из биологии — это нервная клетка; биологическая «нейронная сеть» — это нервная система. Искусственная нейронная сеть можно представить как реляционную базу данных, где коэффициенты связей между ячейками (веса) первоначально неизвестны и задаются псевдослучайно в процессе инициализации. При случайных весах сеть бесполезна — она необучена.
Чтобы «обучить» нейросеть, нужно предоставить ей примеры правильных ответов и алгоритм машинного обучения, который корректирует веса на основе ошибки. Несмотря на громкое название «искусственный интеллект», алгоритм обучения часто не сложнее традиционных алгоритмических процедур.
Программа обучения генерирует случайные значения весов (обычно в диапазоне примерно от -0.5 до +0.5) — это и есть инициализация. Входные признаки умножаются на соответствующие веса, затем для каждого узла суммируются полученные произведения — это и есть прямое распространение (forward propagation). Полученная сумма пропускается через функцию активации, чтобы сжать результат в требуемый диапазон (например, от 0 до 1). Чаще всего в простых примерах используется сигмоида — о ней будет подробнее ниже.
Выход функции активации сравнивается с эталонным значением с помощью функции потерь. На основе величины ошибки корректируются веса (обратное распространение). Этот цикл повторяется много раз, и с каждой итерацией диапазон значений весов сужается, что отражает рост точности сети.
Замена входных данных в обученной нейросети на новые значения позволяет классифицировать или предсказывать эти данные с помощью уже подобранных параметров.
Обладая обученной нейросетью с высокой точностью на тренировочном датасете, можно прогонять через неё новые данные, близкие по характеристикам к обучающим. Уверенность в предсказании равна произведению двух факторов: точности сети на обучающей выборке и степени похожести новых данных на обучающую выборку.
Если сеть обучалась распознавать кошек и собак и достигла 99% точности, она будет хорошо распознавать похожие изображения. Но если передать картинку бобра или синицы, сеть попытается «приписать» её к наиболее похожему классу (кошка/собака), хотя это не будет корректным решением. Иными словами, нейросеть — инструмент классификации и прогнозирования для относительно стабильных или циклически повторяющихся систем.
Примеры стабильных систем: анатомия человека — она меняется очень медленно, что позволяет обучать диагностические модели на соответствующих датасетах. Примеры нестабильных систем: спортивные результаты, фондовый рынок, хаотические физические процессы — там прогнозы оказываются менее надежными и часто развлекательного характера. Алгоритмы для финансов обычно оценивают риск и формируют консервативные стратегии, а не гарантируют сверхприбыли.
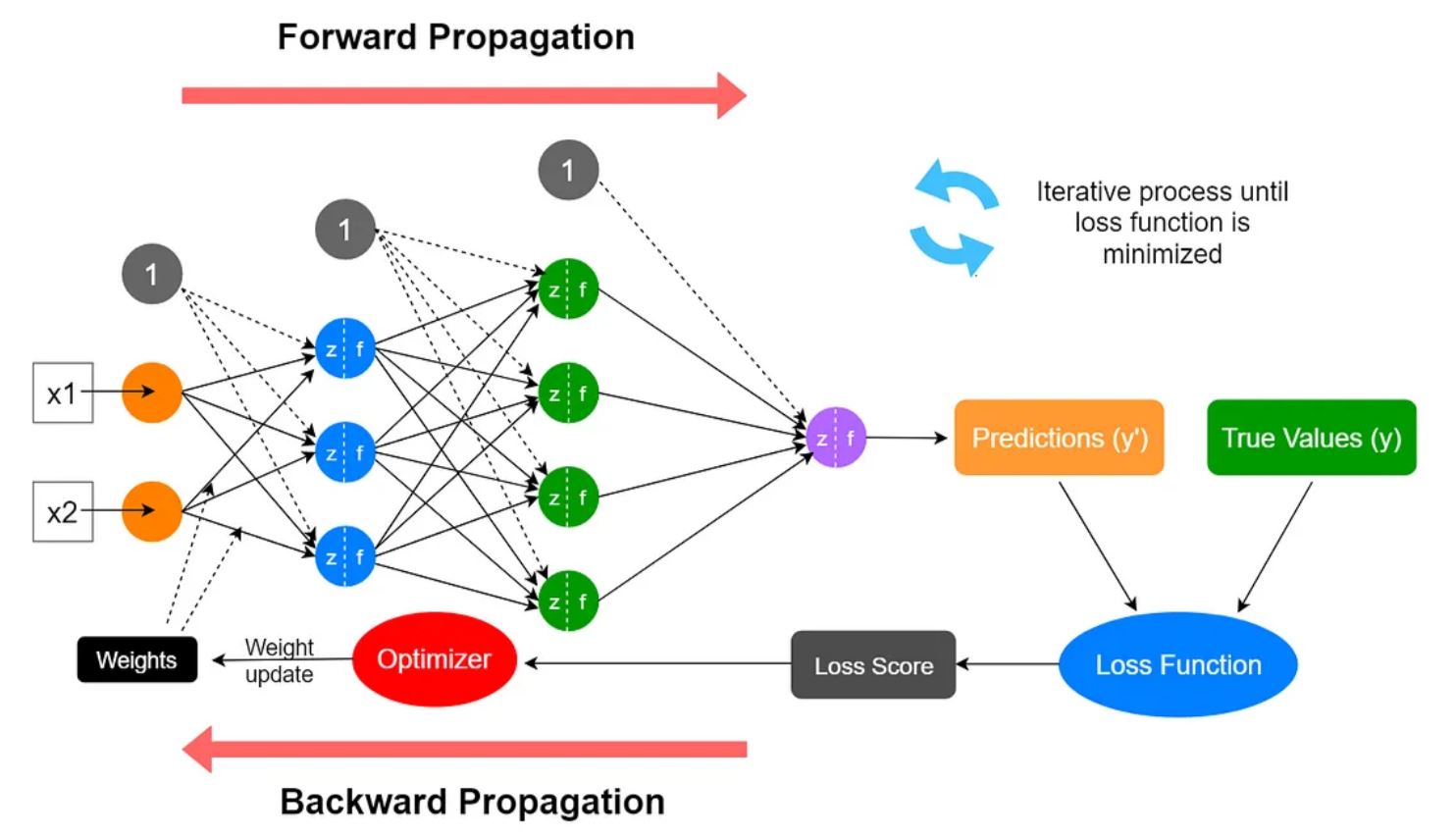
Machine Learning (ML) - алгоритм Машинного Обучения
Прямое распространение (forward propagation) — преобразование входных признаков в выходные значения (классы или прогнозы). Прямое распространение применяет к входам текущие коэффициенты связей (параметры), суммирует вклад каждого узла и пропускает результат через функцию активации.
Прямое распространение определяет значения нейронов (узлов) в сети.
Функции активации и сжатие выходов (ключевые слова: функция активации, сигмоида)
Функция активации — по сути аппроксимация, применяемая когда ответ должен лежать в ограниченном диапазоне. Сумма взвешенных входов может быть неограниченной, поэтому её «сжимают» с помощью функции активации. Одной из классических функций является сигмоида:

Примечание: символ σ также часто используют в формулах среднего квадратичного отклонения, что похоже на среднеквадратичную ошибку (MSE), но математически эти понятия различаются — в MSE нет извлечения квадратного корня.
Обратное распространение ошибки — Backward Propagation (ключевые слова: обратное распространение, функция потерь, производная)
Каждому выходному узлу можно сопоставить класс, после чего итеративно корректировать параметры сети так, чтобы сеть отображала входы в правильные классы. Если прямое распространение — понятная операция умножения и суммирования, то обратное распространение — процесс вычисления вклада каждого веса в общую ошибку и его корректировки.
Обратное распространение — это процесс коррекции параметров сети, который и является по сути процессом обучения. Он начинается с выбора функции потерь и далее опирается на математический инструмент — производную и правило цепочки.
Обратное распространение влияет на значения коэффициентов связей (весов).
Цель обратного распространения — увеличить активацию «правильных» выходных узлов и уменьшить ошибку на остальных. Первый шаг — вычислить вклад функции потерь (стоимости ошибки) из выходного слоя на параметры, ведущие к этому слою.
Математически комплексная функция от параметров сети и функции потерь для выходного узла n может быть записана как композиция активаций и функции потерь. Эта композиция позволяет, с помощью дифференцирования (правила цепочки), найти вклад каждой переменной в общую ошибку и соответственно скорректировать веса.

Эта же формула, записанная через композицию функций, выглядит так:

Здесь z — итоговая функция прямого распространения от всех параметров и функции потерь для выходного узла n; f — функция потерь; σ — функция активации (например, сигмоида); k — число скрытых слоёв; i — число узлов в слое; n — номер выходного класса.
Объединяя все переменные в композитную функцию прямого распространения и применяя правила дифференцирования, можно вычислить частные производные по каждой переменной — это и требуется для обучения при обратном распространении ошибки.
Перед непосредственным описанием обратного распространения стоит кратко остановиться на функции потерь.
Функция потерь: среднеквадратичная ошибка (MSE) — понятие и формула (ключевые слова: MSE, функция потерь)
Существует множество функций потерь для разных задач, но в большинстве случаев в учебных примерах используется среднеквадратичная ошибка (Mean Squared Error, MSE). MSE вычисляет квадрат разницы между прогнозом и эталоном, суммирует квадраты и делит на число слагаемых. MSE удобна своей универсальностью: возведение в чётную степень даёт положительное значение независимо от знака разности.

Во время обучения важна не столько абсолютная величина показателя, сколько его динамика — уменьшение ошибки с итерациями.
В математике для исследования динамики функций используется производная. Производная характеризует скорость изменения функции в точке. В контексте нейросетей частные производные (и правило цепочки) позволяют вычислить вклад каждой связи в общую функцию потерь.
Объявим функцию потерь как функцию от двух переменных:

Тогда общая функция потерь для всех выходных узлов записывается как сумма индивидуальных потерь:

Если использовать среднеквадратичную ошибку как общую функцию потерь, то она принимает вид:

С помощью дифференцирования функции нескольких переменных находим частные производные общей функции потерь по прогнозам (они понадобятся далее при вычислении градиентов), считая остальные слагаемые постоянными:

Примечательно, что этот процесс дифференцирования делает равными между собой производные от общей функции потерь и от какой-либо отдельно взятой функции потерь по какой-то конкретной переменной:

К тому же, множитель (2/n) в данном случае, как и ноль, не играет никакой роли - всё равно дальше всё будет умножено на параметр «шага обучения», который задаётся произвольным образом.
В итоге - в контексте последнего слоя нейросети, частная производная функции потерь (общей или частной) по какому-то конкретному выводу выглядит так:

где i - номер (индекс) выходного узла (класса).
Эту формула напоминает игру «холодно-горячо», где она в буквальном смысле выдаёт значения температуры, только наоборот: при эталоне равном нулю, вычитание нуля из любого значения будет вытекать в положительные значения производной; а при эталоне равном единице - вычитание единицы из любого меньшего числа будет давать отрицательную производную функции потерь.
Положительную производную функции потерь по прогнозам - можно понимать как количество ошибки; а отрицательная производная функции потерь относительно прогнозов - указывает на степень правильности.
К сожалению, такая «обратная» логика не очень хорошо укладывается в общую картину нейросетей, где принято увеличивать значения «на верном пути» и уменьшать ошибку - поэтому полученный результат умножается на отрицательный коэффициент шага обучения - этот множитель определяет скорость обучения, задаётся вручную и его калибровка позволяет снизить количество эпох-итераций обучения, необходимых для достижения приемлемой уверенности в прогнозах.
Производная функции потерь по прогнозам, умноженная на (отрицательный) шаг обучения - это и есть самые первые параметры, рассчитанные в самом начале того, что уже называется «обратным распространением ошибки».
Цепное правило — вычисление градиента для обратного распространения ошибок

В переводе на человеческий язык, формула выше означает, что производная сложной (композитной) функции равна произведению производных - внешней функции и внутренней.
Примечание: в обозначениях Лейбница цепное правило для вычисления производной функции z = z(f), где f = f(x), принимает следующий вид:

Взвешиваемый узел и роль веса в градиенте (определение, ключевые термины)
Для дальнейших определений, введём понятие «взвешиваемого узла» - это следующий за каким-то конкретным весом (параметром) узел (нейрон). При прямом распространении, значения узлов умножаются на «исходящие» из них параметры - так вот, вес в контексте «взвешиваемого узла» - это именно «входящий», а не «исходящий» вес.
Применяя цепное правило относительно коэффициентов связей - можно вычислить частную производную общей функции потерь по весу связи «w» - градиент по параметру «w»
Частная производная общей функции потерь по какому-то весу «w» - равна производной общей функции потерь по выводу взвешиваемого этим весом узла, умноженной на производную вывода (взвешиваемого узла) по вводу (взвешиваемого узла), умноженной на производную ввода (взвешиваемого узла) по этому весу:

примечание: цифры в квадратных скобках перед выражением - означают его «уровень»; я добавил их для наглядности - далее по тексту будет ясно, зачем они. Математического смысла они не несут, в вычислениях не участвуют!
Шаги вычисления частной производной по весу — градиент параметра w
Рассмотрим по отдельности каждый множитель из этой формулы; начнём с первого - производная общей функции потерь по выводу узла «х».
Поскольку общая функция потерь является суммой всех функций потерь,

то это же верно и для её производной (одно из правил):

Перепишем это же уравнение по отношению к выводу какого-то узла «х»:

где n - количество выходных классов; x - индекс взвешиваемого узла.
Каждое слагаемое из этой суммы можно найти по следующей формуле:

где i - целое число от 1 до n, где n - количество выходных узлов нейросети.
При прямом распространении, ввод узла «i» вычисляется простым умножением значения (вывода) узла «x» на коэффициент исходящей из него связи «w»(xi):

Следовательно - искомая в ходе обратного распространения производная ввода следующего слоя от вывода предыдущего - равна коэффициенту связи (весу) между взвешиваемым узлом и этим вводом:

Производная функции потерь по вводу - как сложная функция, раскладывается в произведение производных:

Ну а здесь уже всё «родное» - первый множитель вспомним из недавних расчётов:

По поводу второго множителя - поскольку вывод с какого-либо узла является функцией активации от его ввода,

то производная вывода по вводу - равняется производной от функции активации по этому вводу, применённой в ходе прямого распространения ко взвешиваемому узлу:

Подставим найденные значения в формулу «уровнем» выше:

И ещё выше - в итоге, получаем формулу производной частной функции потерь по выводу взвешиваемого узла:

В этой формуле примечательно использование веса w(xi), исходящего из взвешиваемого узла: именно поэтому данный метод коррекции называется «обратным распространением ошибки» - потому что первыми по порядку корректируются значения выходных параметров, а за ними - на их основе, корректируются более глубокие параметры - и так далее - с последнего слоя нейросети до первого.
Далее - подставляем всё это в формулу производной общей функции потерь по выводу какого-то узла «х»:


где n - количество выходных узлов нейросети; w - параметр, исходящий из взвешиваемого узла.
Вернёмся к «главной» формуле:

Первый множитель - только что обозначенная сумма;
Производная вывода узла по его вводу - это производная от его функции активации:

Производная функции акивации σ'(ввод) и её роль в обратном распространении — вычисление градиента по весам

Производная от ввода по весу — просто равняется предыдущему выводу, из которого идёт связь с искомым весом:


где p - индекс узла из которого идёт связь со взвешиваемым узлом; w(px) - входящая связь во взвешиваемый узел. Смещение (bias) — "голый" вес без коэффициента узла — важный элемент, без которого нейросеть работает менее точно, чем с ним. Ну правда — я не знаю как лучше его объяснить, да и зачем? Иногда лучше просто "shut up and calculate".
Итоговый градиент: производная общей функции потерь по весу w до узла x — формулы для последнего слоя и скрытых слоёв (градиент, обратное распространение)
для узла "х" из последнего слоя:

для узла "х" из всех остальных слоёв:

где x - индекс взвешиваемого узла; p - индекс "исходящего" узла; n - количество выходных узлов в нейросети; х ∉ p ∉ n
Примечания к формулам градиента и обозначения (weights, bias, индексы)
если индекс p относится к "узлу смещения" (bias), то переменная "вывод(р)" упраздняется в единицу;
w(px) — вес связи от узла "p" до узла "x";
w(xi) — вес связи от узла "х" до узла "i".
Архитектура нейронной сети: вводы, слои, скрытые слои, смещения и функции активации — ключевые компоненты
Итак, нейросеть — это некоторое множество "вводов", на каждый из которых поступают данные из разных источников (подобно нервным окончаниям у людей) и связи различной силы этих "вводов" с "выводами", которые эта нейросеть делает из полученных данных. Что-то ещё?
Ну, во-первых — прямая связь "ввода" с "выводом" — это то, что называется одним "слоем" нейронной сети, а таких слоёв может быть множество — где "вывод" одного слоя — это "ввод" следующего. Если у нейронной сети больше одного слоя, то все "промежуточные" слои — называются "скрытыми" (hidden). Когда у нейросети более одного скрытого слоя — то такая сеть считается "глубокой" — от термина "глубокое обучение" (deep learning), посвящённого, собственно, обучению таких сетей. Смысл таких слоёв (и "глубокого обучения") в том, чтобы усложнить связи между вводом и выводом — добавить коэффициенты к коэффициентам, позволяющие более гибко адаптировать их значения под требуемые результаты.
С увеличением количества скрытых слоёв и количества узлов в этих слоях увеличивается "выразительность" сети — её способность выделять зависимости и закономерности во входных данных. Однако с увеличением сложности сети, каждый следующий слой поднимает затраты на обучение такой сети — в геометрической прогрессии; кроме того — слишком "сложная" нейросеть — с избытком скрытых слоёв — будет страдать от "переобучения" — это когда нейросеть слишком хорошо "запоминает" обучающий датасет и утрачивает способность обобщать его на новые данные. Поэтому — выбор оптимального количества скрытых слоёв и количества узлов в этих слоях является важной задачей при проектировании нейросети и требует тщательного анализа и экспериментов.
Во-вторых — так называемые "нейроны смещения" — узлы с фиксированным значением — добавляются к каждому скрытому слою и не имеют "входных" связей: своеобразные усилители сигнала.
В-третьих — "функция активации" — по сути просто аппроксимация; применяется в тех случаях, где ответ должен укладываться в конечный диапазон. Например — функция активации ReLU.
Ну и последнее — "функция потерь" — это первый градиент, с которого начинается обратное распространение.
Семь базовых логических элементов нейронной сети — входы, веса, смещения, слои, активация, потеря, выход
входные узлы (особенности)
коэффициенты связей (параметры)
узлы смещения (bias)
скрытые слои
функция активации
функция потерь
выходные узлы (прогнозы)
Всего-то 7 штук! И все известны уже более 30 лет.
Пример реализации классификатора MNIST на Python — подготовка данных и структура программы
Теперь — подробно разберём программный код нейросети на питоне — классификатора изображений, способного определять, на какую из десяти различных цифр больше всего похоже данное ему изображение.
Программа состоит из трёх частей: учебный датасет "MNIST" (который скачивается по этой ссылке), состоящий из 60 тысяч картинок цифр с названиями; программный модуль, преобразующий данные из этого датасета и, собственно, код самой нейросети. Сначала — код модуля get-mnist:
# модули numpy и pathlib должны быть установлены в питон
import numpy as np
import pathlibФункция get_mnist — загрузка и предобработка датасета MNIST (images, labels, one-hot)
Объявление функции "get_mnist", которая будет возвращать значения, указанные ниже в команде return (images и labels).
def get_mnist():
# Из файла извлекается два массива: images (из ключа "x_train") и labels (из ключа "y_train"). x_train содержит изображения цифр, а y_train - соответствующие им метки (цифры от 0 до 9).
# Примечание: предполагается, что файл mnist.npz размещён в папке data, которая находится в папке со скриптом.
with np.load(f"{pathlib.Path(__file__).parent.absolute()}/data/mnist.npz") as f:
images, labels = f["x_train"], f["y_train"]
# Преобразуем тип данных массива images в float32 и сожмём значения в диапазон от 0 до 1 путем деления на 255.
images = images.astype("float32") / 255
# images - трёхмерный массив двухмерных картинок, [0] измерение это количество картинок, а измерения [1] и [2] - размерности по высоте и ширине. Умножив размерности [1] и [2] друг на друга - получается общее количество пикселей в изображении. На выходе получается двухмерный массив - матрица.
images = np.reshape(images, (images.shape[0], images.shape[1] * images.shape[2]))
# Здесь метки преобразуются в формат "one-hot encoding". Мы создаем матрицу размером 10x10, где каждая строка представляет одну метку (цифру от 0 до 9). Значение 1 в строке соответствует метке, а остальные значения равны 0.
labels = np.eye(10)[labels]
# Функция возвращает два массива: images (обработанные изображения) и labels (one-hot encoded метки).
return images, labelsДалее — разберём код самой нейросети — программы машинного обучения:
Нейросеть для классификации изображений MNIST — архитектура, обучение и прямое/обратное распространение
# Ниже код программы машинного обучения искусственной нейросети - классификатора изображений
from data import get_mnist
import numpy as np
import matplotlib.pyplot as plt
"""
w = weights (вес), b = bias (смещение), i = input (ввод), h = hidden (скрытый), o = output (вывод), l = label (правильный ответ)
e.g. w_i_h = weights from input layer to hidden layer (вес_ввод_скрытый - вес связи между вводом и скрытым слоем)
"""
# Загрузка данных из датасета
images, labels = get_mnist()
# Инициализация весов случайными числами
w_i_h = np.random.uniform(-0.5, 0.5, (20, 784))
w_h_o = np.random.uniform(-0.5, 0.5, (10, 20))
# Инициализация смещений нулями
b_i_h = np.zeros((20, 1))
b_h_o = np.zeros((10, 1))
# learn_rate - шаг обучения, epochs - количество итераций, nr_correct - отслеживает количество правильных предсказаний
learn_rate = 0.2
nr_correct = 0
epochs = 3
# Цикл обучения
for epoch in range(epochs):
# Чтобы numpy мог посчитать скалярное произведение, необходимо подготовить одномерные матрицы img и l; использование zip ползволяет обрабатывать соответствующие элементы из нескольких массивов одновременно
for img, l in zip(images, labels):
img.shape += (1,)
l.shape += (1,)
# Прямое распространение ввод -> скрытый слой: вес смещения ввода суммируется с произведениями вводов и их весов (произведения между собой так же суммируются)
h_pre = b_i_h + w_i_h @ img
# Применение функции активации "сигмоида": np.exp - функция экспоненты - возведение числа Эйлера в степень, указанную в скобках. При возведении экспоненты в отрицательные степени - результат стремится к нулю, а при возведении в положительные - к бесконечности
h = 1 / (1 + np.exp(-h_pre))
# Прямое распространение скрытый слой -> вывод: вес смещения скрытого слоя суммируется с произведениями значений узлов скрытого слоя и их весов (произведения между собой так же суммируются)
o_pre = b_h_o + w_h_o @ h
# Применение функции активации "сигмоида"
o = 1 / (1 + np.exp(-o_pre))
# Стоимость ошибок, она же Функция потерь (на примере среднеквадратической ошибки; в данном коде эта переменная никак не используется и оставлена просто для наглядности)
# e = 1 / len(o) * np.sum((l - o) ** 2, axis=0)
# Если ячейка с максимальным значением в слое вывода совпадает с ячейкой с максимальным значением в одномерной матрице l - labels - то счётчик правильных ответов увеличивается
nr_correct += int(np.argmax(o) == np.argmax(l))
# Обратное распространение вывод -> скрытый слой (производная функции потерь)
delta_o = (2/len(o)) * (o - l)
# К весу от скрытого слоя до вывода (на каждый нейрон соответственно) добавляется произведение его правильности на шаг обучения: у ошибочных результатов показатель отрицательный и, следовательно, он вычитается.
# Транспонирование матриц - необходимо для их умножения. Операция умножения двух матриц выполнима только в том случае, если число столбцов в первом сомножителе равно числу строк во втором; в этом случае говорят, что матрицы согласованы.
w_h_o += -learn_rate * delta_o @ np.transpose(h)
b_h_o += -learn_rate * delta_o
# Обратное распространение скрытый слой -> ввод (производная композитной функции - производная функции активации умноженная на производную функции потерь))
delta_h = np.transpose(w_h_o) @ delta_o * (h * (1 - h))
w_i_h += -learn_rate * delta_h @ np.transpose(img)
b_i_h += -learn_rate * delta_h
# Показать точность прогнозов для текущей итерации обучения и сбросить счётчик правильных прогнозов
print(f"Уверенность: {round((nr_correct / images.shape[0]) * 100, 2)}%")
nr_correct = 0
# Показать результаты - запрашивает у пользователя номер картинки, которая будет пропущена через нейросеть прямым распространением, в результате которого нейросеть предскажет какая цифра на картинке
while True:
index = int(input("Введите число (0 - 59999): "))
img = images[index]
plt.imshow(img.reshape(28, 28), cmap="Greys")
# Прямое распространение ввод -> скрытый слой
h_pre = b_i_h + w_i_h @ img.reshape(784, 1)
# Активация сигмоида
h = 1 / (1 + np.exp(-h_pre))
# Прямое распространение скрытый слой -> вывод
o_pre = b_h_o + w_h_o @ h
# Активация сигмоида
o = 1 / (1 + np.exp(-o_pre))# argmax возвращает порядковый номер самого большого элемента в массиве
plt.title(f"Нейросеть считает, что на картинке цифра {o.argmax()}")
plt.show()Этот пример с классификацией цифр датасета MNIST — можно считать «hello world» задачей из мира нейросетей: достаточно наглядный и при этом не слишком сложный код. Если его понимание не вызвало трудностей и интерес к теме сохранился — можно дополнить список функций активации (начинайте с ReLU — она самая популярная) — wikipedia
Как нейросети генерируют изображения: генерация изображений нейросети, свёртки и шум
Окей, с тем, как нейросети классифицируют объекты — разобрались: даны входные данные, эталонные метки и случайно инициализированные параметры, которые подстраиваются под данные в процессе обратного распространения ошибки.
Тот же принцип — но применённый не к параметрам, а к значениям узлов первого слоя (слоя ввода) — «лёгким движением руки» превращает обученную нейросеть‑классификатор в генератор новых данных (например, изображений).
Значения узлов вводного слоя изменяются на произвольные величины (в данные вводится шум или данные полностью заменяются шумом). Эти изменения проходят прямым распространением по обучённой нейросети до выходов, которые меняются в соответствии с изменениями ввода. По динамике этих изменений нейросеть отслеживает, какие изменения и на каких узлах ввода лучше соответствуют требуемым выходам, а какие — хуже. Таким образом, за каждую итерацию «примеряя» к требуемым выходам небольшие произвольные изменения данных (например, цвета пикселей), отбрасывая неподходящие значения и закрепляя подходящие, нейросеть за множество итераций формирует наиболее подходящий под запрошенные выходы результат, как бы «рассевая» перекрывающий его шум.
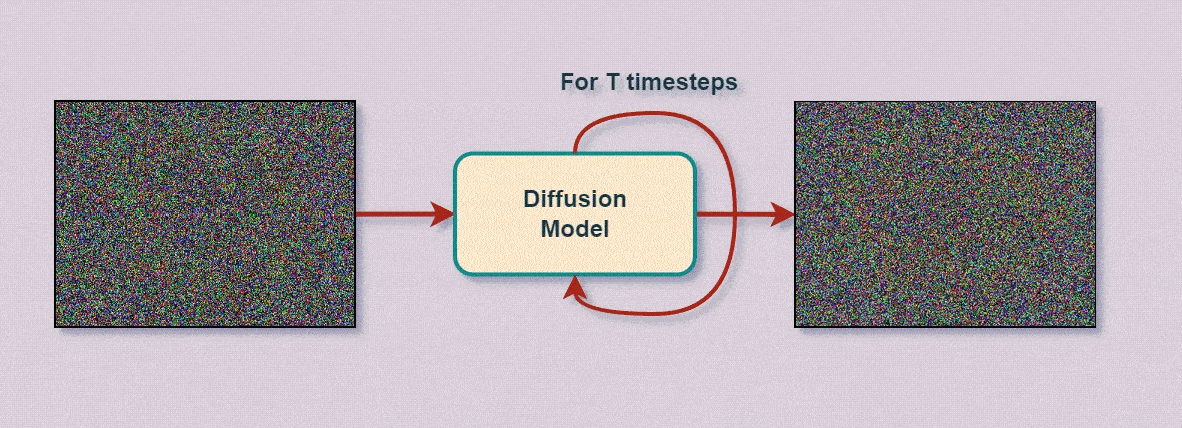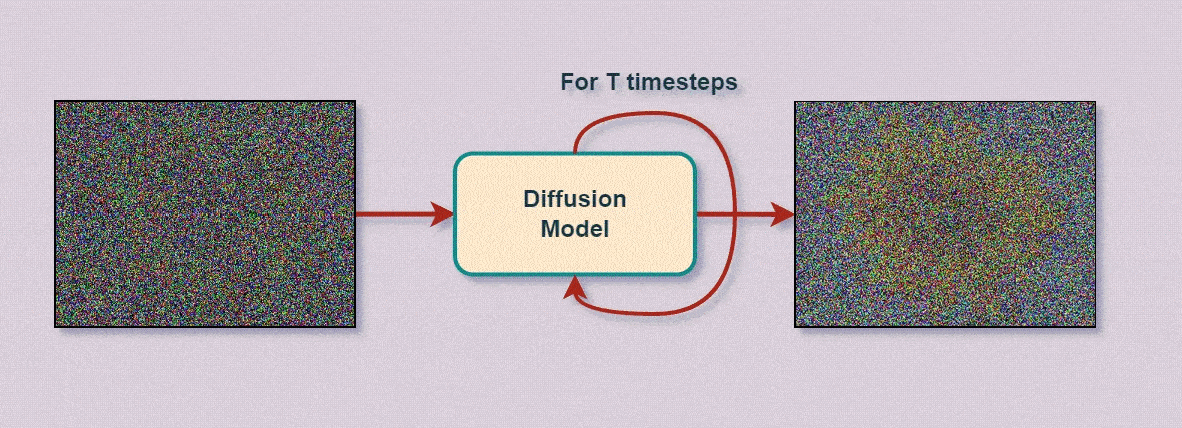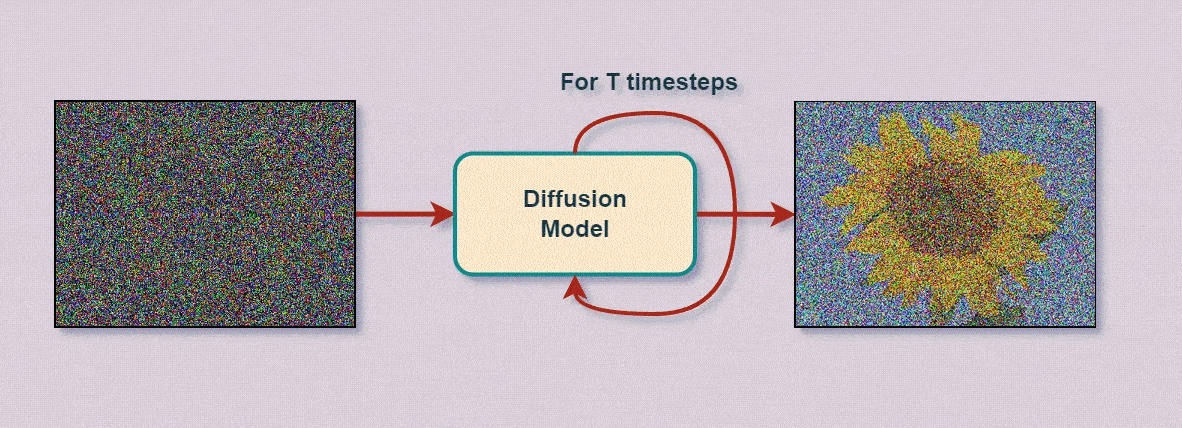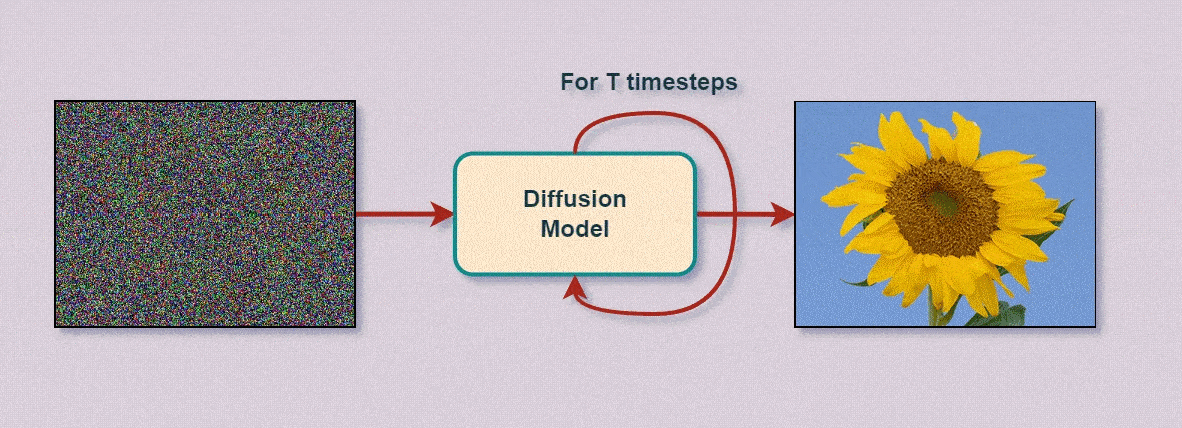
Понятно, что ничего не понятно
Понятно, что ничего не понятно
Например, у нас есть нейросеть‑классификатор, обученная на различных изображениях, среди которых есть подсолнух. Показывая нейросети этот (или любой другой) подсолнух, мы вводим определённую последовательность данных (значения пикселей на входном слое), которые, проходя по узлам и параметрам, в итоге дают наибольшую активацию для класса «подсолнух». Естественно, «реакция» нейросети будет отличаться для разных изображений: условно говоря, относительно нейросети некоторые подсолнухи будут выглядеть «более подсолнечными» — просто снятыми с другого ракурса или при другом освещении.
Если вводить в изображение подсолнуха небольшой случайный шум (меняя значения пикселей на малые величины), будет меняться и уверенность нейросети в том, что перед ней всё ещё подсолнух. Постоянно добавляя шум, рано или поздно исходное изображение станет неразличимым — изнутри нейросети это проявится как падение уверенности по всем классам.
Теперь «дело за малым» — попытаться обратить процесс добавления шума примерно так же, как обратное распространение обращает прямое. Но шум — случайен, и обратить его не так просто: случайный шум часто безвозвратно удаляет часть информации. Задача восстановления информации требует, во‑первых, алгоритма, отличающего «шум» от «не шума», и, во‑вторых, механизма замены найденного шума на данные, максимально подходящие по контексту. Как бы с этой задачей подошёл человек? Давайте проверим — перед монитором как раз есть такой человек.

На какой картинке больше шума?
На какой картинке больше шума?
Очевидно, что шума больше на правой картинке. Но почему? Чем мы можем характеризовать помехи? Посмотрим на картинки поближе.

Ну пиксели и пиксели.
Ну пиксели и пиксели.
Если взять два увеличенных участка с этих картинок и сравнить их, не всегда будет так же очевидно, на каком участке больше шума, как это было с исходниками. В увеличенных фрагментах перед нами могут быть две примерно одинаково хаотичные картинки.
Шум — это некое измерение хаоса в системе, и эта мера зависит от масштаба изображения: в масштабе увеличенного фрагмента 10×10 пикселей мера хаоса окажется выше, чем в составе исходного, значительно большего изображения. Почему? Потому что больший масштаб содержит в себе больше смысловых элементов, чем меньший. С общего плана мы видим, что слева — горы, камни, вода, небо; справа — люди и воздушные шары. Поняв это, нам становится очевидно, что на горах слева меньше шума, чем на шариках справа — потому что мы сравниваем найденные на изображениях образы с эталонными (воспоминаниями) и по количеству отличий судим о количестве шума. Мы знаем, как обычно выглядят люди, шарики и горы — это позволяет нам замечать «лишние» пиксели шума.
Свёрточные нейросети (CNN) и U‑Net: свёртка, выделение смысловых элементов и ядро свёртки
Именно этот принцип лежит в основе работы свёрточных нейросетей (CNN), наиболее известной из которых является архитектура U‑Net — её схема напоминает букву U. Свёрточные сети смотрят на общий план изображения, выделяют смысловые элементы и соотносят их с накопленным в процессе обучения опытом. То, что мы назвали «посмотреть на картинку шире», в терминологии нейросетей — это «свёртка» (convolution). В результате свёртки сеть абстрагируется от отдельных пикселей к смыслу отдельных элементов, а затем — к смыслу всей картинки.
Свёртка — это по сути сжатие (с потерями), отчасти напоминающее вычисление хеш‑суммы: исходные данные преобразуются в меньшую матрицу представлений, причём разные исходные данные дают различающиеся представления (в пределах разумного). Сопоставлять объекты по их «свёрткам» гораздо быстрее, чем сравнивать несжатые объекты, и благодаря этому нейросети способны в реальном времени обрабатывать визуальные данные даже на мобильных чипах.
Ключевая разница между обычным классификатором и свёрточной сетью — в параметрах: у классификатора параметры инициализируются случайно и затем подстраиваются, а у свёрточной сети ядра свёртки (фильтры) изначально устроены так, чтобы одновременно сжимать данные, сохранять смысловые элементы и выделять границы переходов между ними. Этот приём настолько эффективен, что с его помощью можно, например, добавить тени на плоские объекты — принцип работы многих «прикольных» фильтров в графических редакторах.
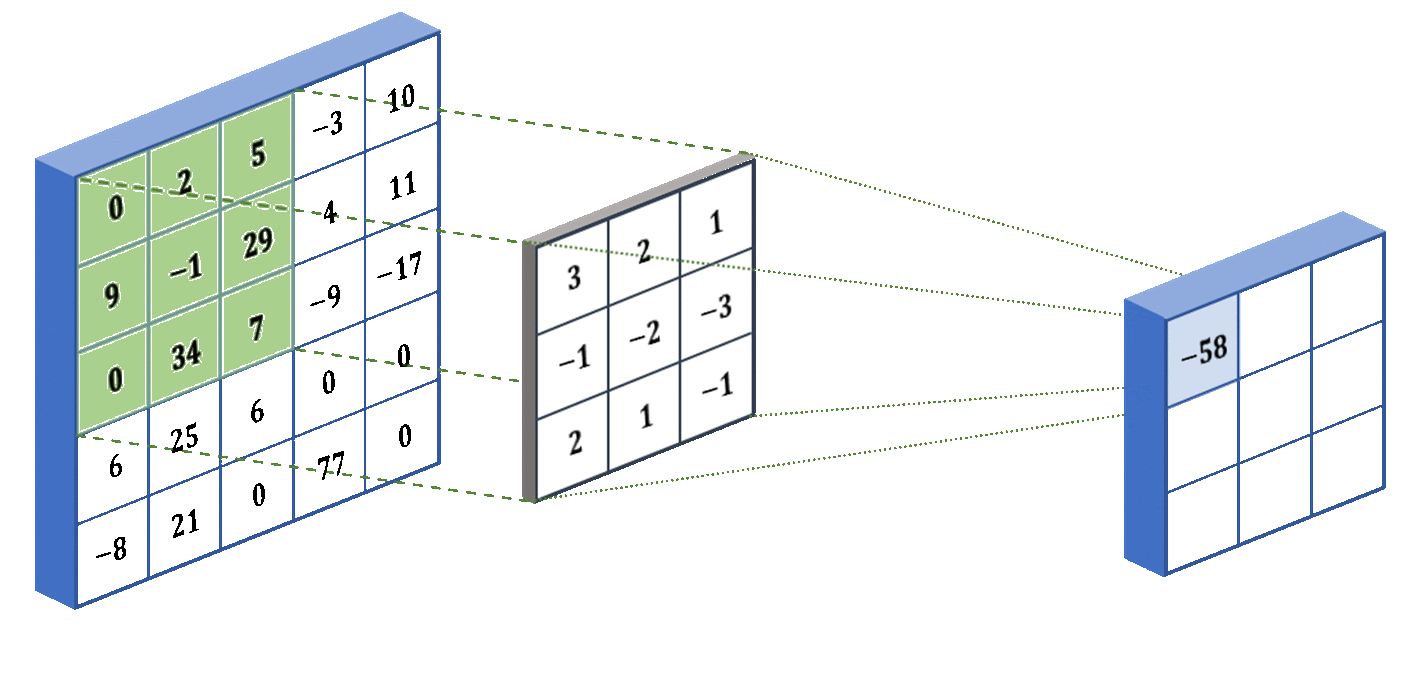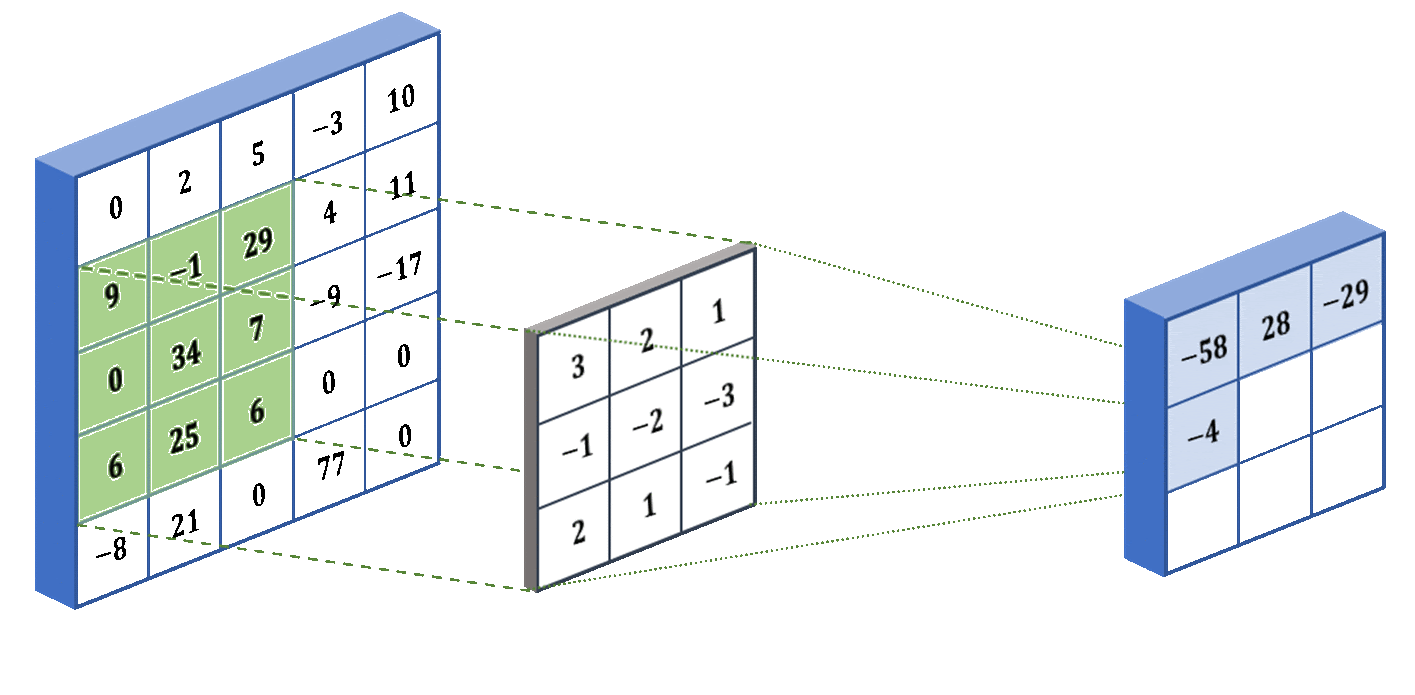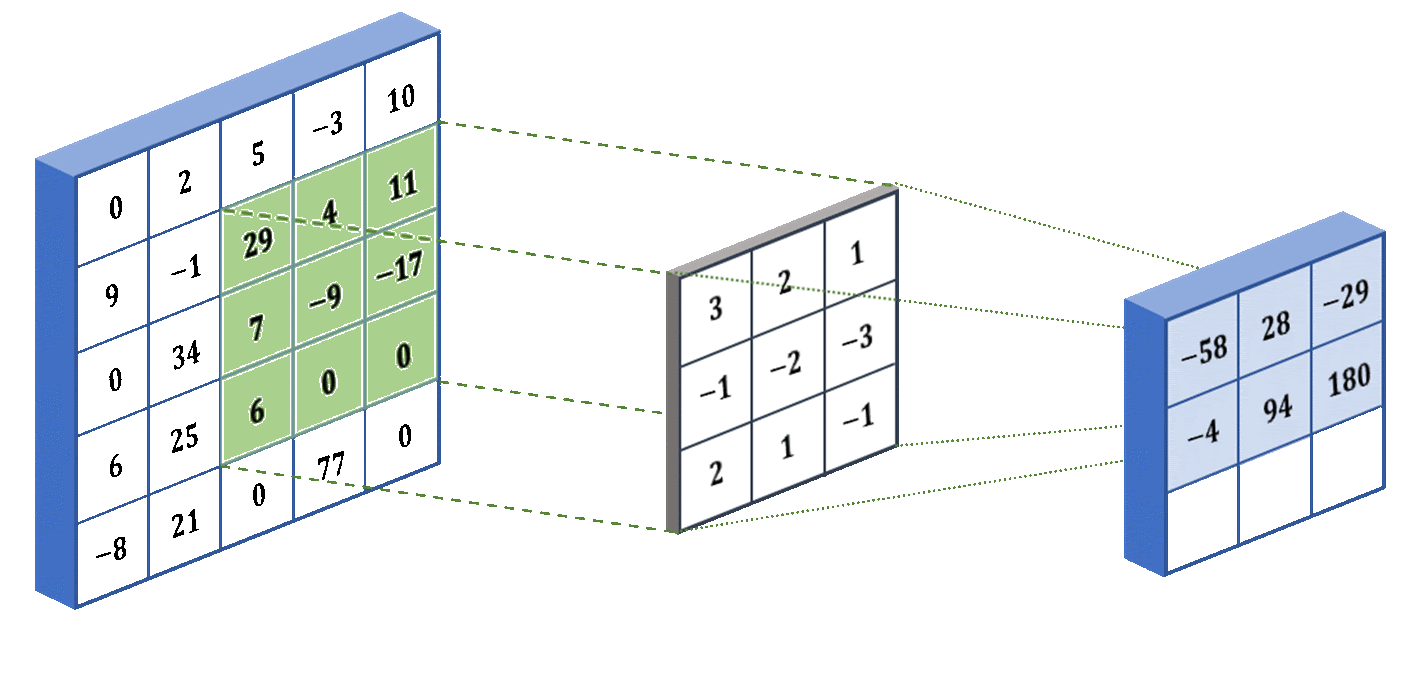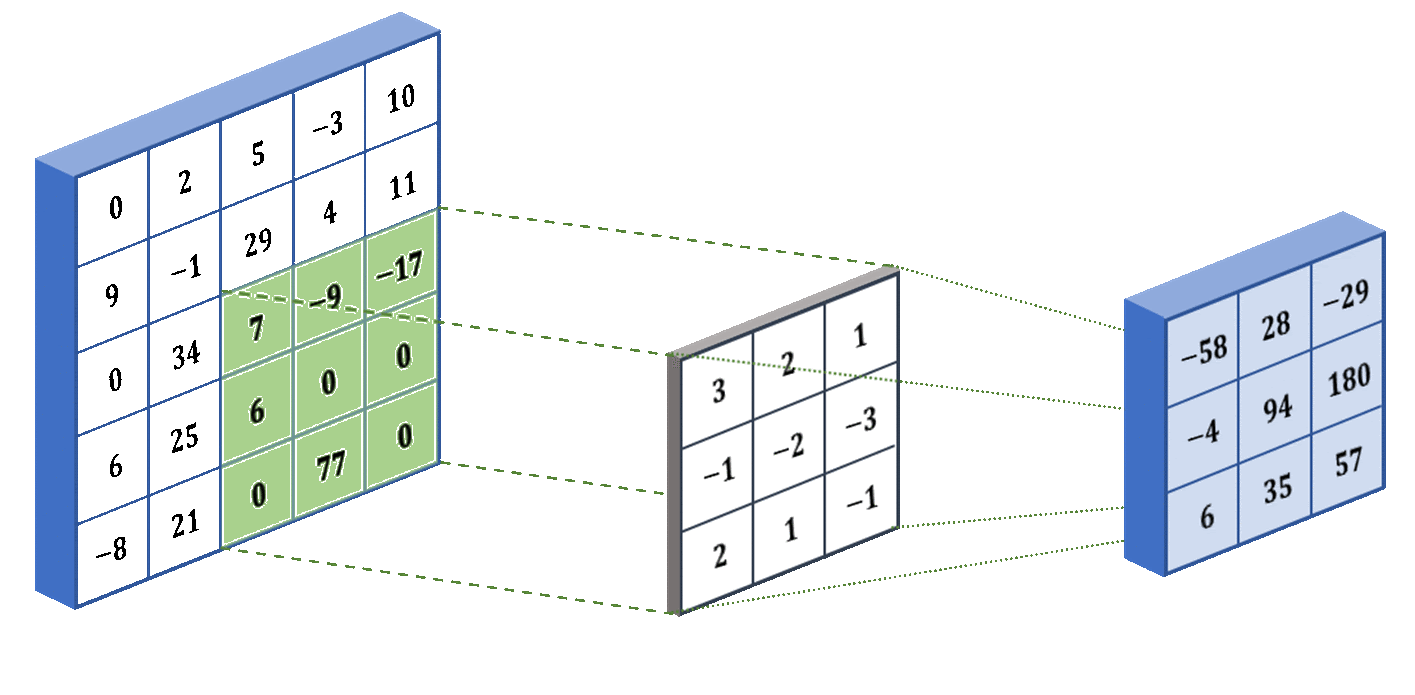
U-Net: процесс свёртки. Слева - ввод, посередине - фильтр (ядро свёртки), справа - свёртка. Процесс можно повторять и для свёрток, в результате - сжимая исходник насколько угодно.
U‑Net: процесс свёртки. Слева — ввод, посередине — фильтр (ядро свёртки), справа — свёртка. Процесс можно повторять и для свёрток, сжимая исходник насколько угодно.
Как видно из анимации выше, процесс прост: по входной матрице проходит маска (ядро свёртки) с некоторыми значениями. Маска умножает значения в перекрывающихся ячейках матрицы на свои коэффициенты, затем суммирует результаты и записывает одно результирующее значение в соответствующую ячейку выходной матрицы. Степень сжатия зависит от размера ядра свёртки и количества применений. В общем случае матрицу произвольного размера можно сжать до размеров ядра за достаточно большое число итераций.
Вот как выглядит свёртка на конкретном примере (взято из этой статьи):

Слева - оригинал; справа - свёртка. Конкретно это ядро свёртки - увеличивает разницу значений на границах - так называемый 'фильтр улучшения чёткости'. Матрица этого ядра свёртки - на картинке ниже.
Слева — оригинал; справа — свёртка. Это ядро свёртки увеличивает разницу значений на границах — фильтр улучшения чёткости. Матрица ядра свёртки показана ниже.
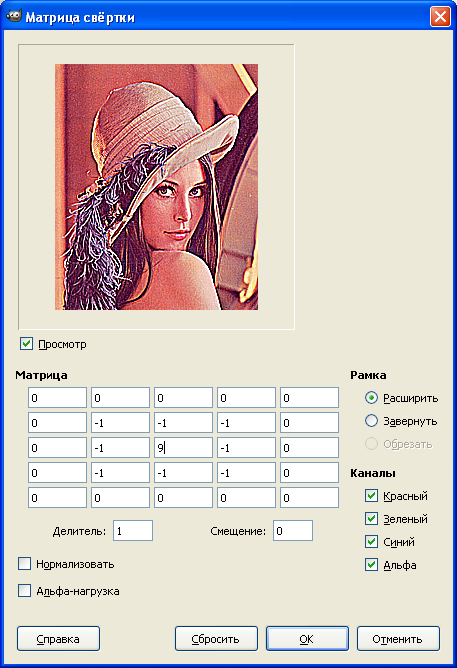
В бесплатной программе GIMP есть наглядный инструмент: фильтры -> общие -> «Матрица свёртки»
В бесплатной программе GIMP есть наглядный инструмент: фильтры -> общие -> «Матрица свёртки»
Ниже — примеры базовых масок 2×2 и 3×3, разделённые по вертикальным и горизонтальным составляющим.
Маски Робертса:
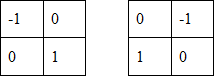

Слева - оригинал; справа - сумма 'горизонтальной' и 'вертикальной' свёрток
Слева — оригинал; справа — сумма «горизонтальной» и «вертикальной» свёрток
Маски Собеля:
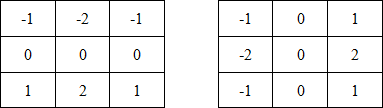

Маски Собеля дают менее точные грани, чем более 'шустрый' аналог Робертса, зато - они менее чувствительны к шуму, благодаря чему на практике более популярны.
Маски Собеля дают менее точные грани, чем более «шустрый» аналог Робертса, зато они менее чувствительны к шуму, благодаря чему на практике более популярны.
Ядра свёртки Робертса и Собеля используются для выделения граней на изображениях. Каждая маска по отдельности выделяет только вертикальные или только горизонтальные грани; на примерах выше показана сумма таких свёрток, дающая все грани в совокупности.
Пулинг и Max Pooling: сжатие изображений, max pooling vs average pooling
Если цель — не выделение граней, а сжатие представления изображения, существует простой алгоритм свёртки‑пулинга — Max Pooling. Он сохраняет максимальное значение из каждой группы ячеек, удаляя остальные, и за один проход сжимает исходник в 4 и более раз.
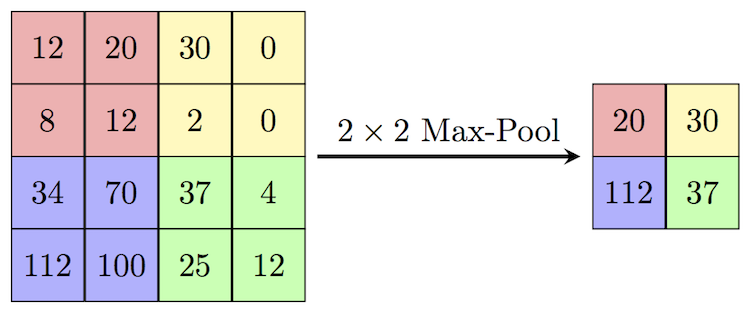
Max Pooling - самый популярный способ 'пулинга' в нейросетях.
Max Pooling — самый популярный способ «пулинга» в нейросетях.
Max pooling — самый распространённый, но далеко не единственный способ пулинга — методов придумали множество, включая генетические и пирамидные подходы.
Почему же max pooling более популярен, чем average pooling? На наглядном сравнении видно, что сжав изображение в 65 раз, max pooling лучше сохранил усы, а average pooling — глаза.

сжав картинку в 65 раз, max pooling лучше сохранил усы, а average pooling - лучше сохранил глаза
Сжав картинку в 65 раз, max pooling лучше сохранил усы, а average pooling — лучше сохранил глаза.
Пулинг может дать непредсказуемые результаты при применении к исходному изображению, поэтому чаще пулингу подвергают не сами исходники, а их свёртки с выделенными переходами и границами.

другое дело! и усы, и глаза - всё на своих местах, да и разницы практически нет, но max pooling всё же чуточку лучше?
другое дело! и усы, и глаза - всё на своих местах, да и разницы практически нет, но max pooling всё же чуточку лучше?
U-Net: свёртки, выделение границ и роль max pooling в архитектуре
А вот и та самая U-Net, на схеме которой синими стрелочками изображены операции выделения граней свёрткой, а красными - пулинг максимальных значений:
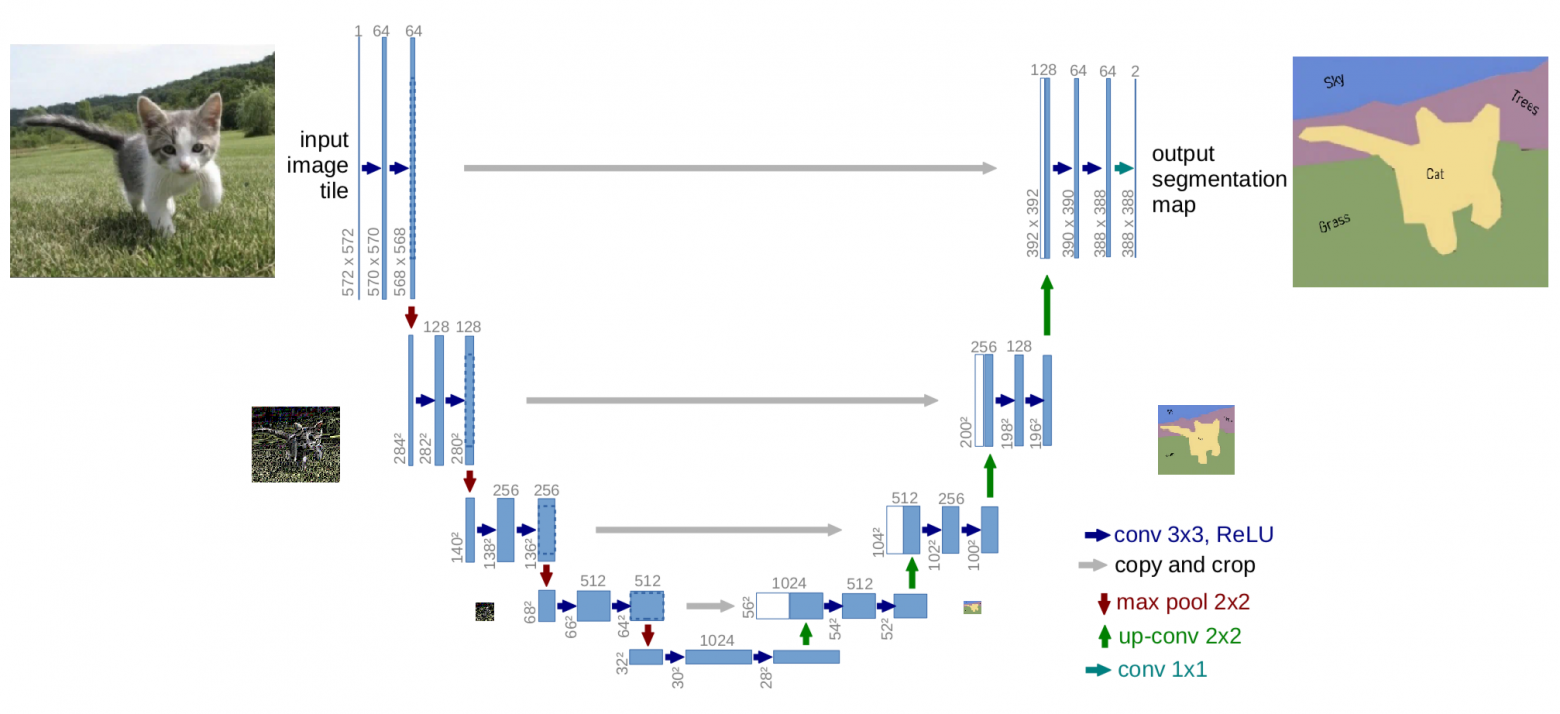
при ядре свёртки 3х3, размерности слоёв свертки всегда различаются на 2 по горизонтали и 2 по вертикали. Если нет - значит используется "костыль", расширяющий матрицы за их границы.
при ядре свёртки 3х3, размерности слоёв свертки всегда различаются на 2 по горизонтали и 2 по вертикали. Если нет - значит используется "костыль", расширяющий матрицы за их границы.
Подавление шума перед свёртками: медианный фильтр (median filter) и его преимущества
Вернёмся к вопросу распознания и коррекции шума. Если на вход свёрточной нейросети подать картинку с сильными помехами - то свёртка такой нейросети масками, выделяющими границы перехода - лишь усугубит ситуацию: перед такими свёртками, входные данные уместно пропустить через "медианный фильтр" - обычно это маска 3х3 или 5х5, на выходе у которой - самое среднее значение из всех, которые попадают в область маски. Медианный фильтр - эффективное средство подавления случайных аномалий (шума) - но это всё ещё ни в коем смысле не средство восстановления информации.

Слева - оригинал; справа - медианный фильтр 7х7. Помните магнитофоны VHS?
Слева - оригинал; справа - медианный фильтр 7х7. Помните магнитофоны VHS?
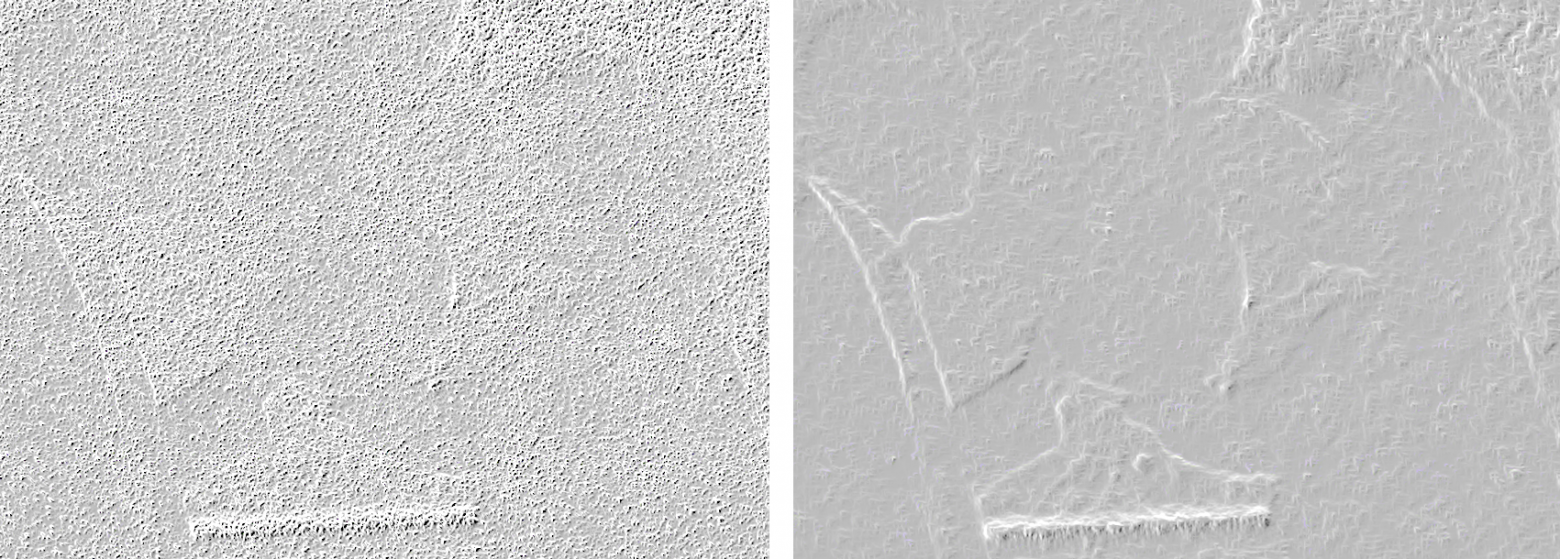
свёртка оригинала и свёртка после медианного фильтра: на последней значительно меньше граней относятся к шуму и больше - к реальным объектам
свёртка оригинала и свёртка после медианного фильтра: на последней значительно меньше граней относятся к шуму и больше - к реальным объектам
Ограничения текст-в-изображение: diffusion-модели, Stable Diffusion и проблема создания шума
Так о чём это я? Ах да - нейросети, превращающие текст в картинки. Но какой текст? Где условия? Неужели можно ввести прямо таки что угодно, и нейросеть нарисует?! Лукавят, лукавят эти "дата саентисты"! Что, с руками проблемы? Пальцев многовато? Нет, не туда смотрите. Пальцы, волосы, прочие неестественности - это всё ерунда, которая легко решается нормальным датасетом, архитектурой и обучением. То что нейросети уделяют недостаточно внимания каким-то деталям - как говорится, "дело техники" - пройдёт несколько лет и эти проблемы уйдут в историю. Но есть кое-что, чего "диффузионные" модели не нарисуют - хоть ты тресни! Уже догадываетесь? Вот вам несколько запросов и их результаты - от одной из самых популярных и самых "мощных" среди публично доступных нейросетей - stable diffusion:

"noisy image of mountains"
"noisy image of mountains"
Я вижу "mountains", но я не вижу "noise". Может быть, я не так смотрю, или не тот запрос? Попробуем другой, чуть более конкретный:

"very bad quality, noisy image, very rubbish and low resolution picture of nature, add noise effect"
"very bad quality, noisy image, very rubbish and low resolution picture of nature, add noise effect"
И снова неудача! Снова - из всего моего длинного и очень конкретно сформулированного запроса, нейросеть поняла только одно слово "nature".
Не сдаёмся (пока бесплатные генерации ещё есть):

"show two images of same place but one with noise and other without noise to show the difference between noisy image and clear image"
"show two images of same place but one with noise and other without noise to show the difference between noisy image and clear image"
Запрошенной разницы между картинками - лично я не вижу. По моему скромному мнению - количество шума с обоих сторон одинаковое.
Широко известная нейросеть ChatGPT прекрасно понимает, что такое пиксели, что такое шум и в чём разница между картинкой низкого разрешения и картинкой высокого разрешения. Современные, хорошо обученные нейросети это понимают, но результат дать не могут. В чём же дело?
Почему GAN (Generative Adversarial Networks) не "воссоздают" шум: роль состязательного элемента и ограничения генерации
А дело всё в последнем элементе таких вот генеративных нейросетей - благодаря которому их полное название - это "Генеративно-состязательные сети" (Generative adversarial network, сокращённо GAN): речь о том самом состязательном элементе этих нейросетей, назначение которого - "лупить палкой" по генератору, если его "творение" хоть чем-то не устраивает состязателя. Именно поэтому генеративно-состязательные сети показывают нам "залипательные" картинки, как бы "отполированные" до блеска - но не могут показать нам всё то, что "состязатель" помечает "браком"; а бракует он всё то, что вызывает у него "смешанные" чувства - все результаты, которые вызывают у нейросети недостаточную (достаточность задаётся администратором) активацию по классам, соответствующим текстовому запросу пользователя, или же если активация по "плохим" классам (тоже задаются администратором) слишком высокая - например, если у нейросети-классификатора, выступающего в роли состязателя, глядя на выдачу псевдослучайного генератора возникает слишком высокий вывод по классу "шум" - то такой состязатель попросит генератор изменить выдачу - но не сильно - на небольшой определённый шаг. Генератор, по запросу состязателя, внесёт изменения в данные на входном слое нейросети (который теперь, как бы, в роли вывода, где формируется картинка) - на что состязатель ему скажет - в правильном ли направлении были внесены изменения или нет. Если направление не правильное - оно меняется, если правильное - то дополняется. Вот так - внося небольшие изменения в данные (например, в цвет пикселей), за множество итераций, данные на входном слое нейросети подгоняются под максимальный вывод по запрошенным классам и минимальный вывод по "запрещённым" классам (которые обычно связаны с шумом и низким качеством изображения, цензурным контентом и "счётчиком пальцев" - в качестве примера).
Выходит, что раньше - нейросети рисовали руки со странными количествами пальцев, теперь же - не могут выполнить запрос, требующий нарисовать руку с числом пальцев, отличным от пяти:

из крайности в крайность...
из крайности в крайность...
Апскейлинг и развитие деталей: как нейросети "врисовывают" пиксели вместо восстановления
Точно так же нейросети и "восстанавливают" информацию, удалённую шумом: строго говоря, они её не восстанавливают, а заменяют наиболее подходящей по контексту. В отличие от медианного фильтра, по сути просто "размазывающего" картинки, заменяющего шум средним значением окружающих его пикселей - генеративно-состязательная нейросеть работает с пикселями отдельно от их соседей - но в связке со смысловым содержанием, которое они учатся выделять с помощью обучения размеченным датасетом. Благодаря такой логике, нейросети могут восстанавливать тонкие линии (даже в один пиксель) и увеличивать разрешение изображений, "врисовывая" между пикселями исходного изображения наиболее подходящие по смыслу:

лица людей содержат "черты" - мельчайшие элементы, на которые заточено человеческое восприятие, поэтому "апскейлинг" (upscaling) в случае с людьми работает... так себе
лица людей содержат "черты" - мельчайшие элементы, на которые заточено человеческое восприятие, поэтому "апскейлинг" (upscaling) в случае с людьми работает... так себе
Источники и ссылки: дополнительные материалы по нейросетям, фильтрам и pooling
Источники и ссылки на дополнительные материалы по теме:
Плагин для Экселя "Nerual Excel" - youtube
Матричные фильтры обработки изображений - хабр
Pooling In Convolutional Neural Networks
Pooling Methods in Deep Neural Networks, a Review - PDF
Классификатор изображений на питоне - youtube
Ряды Тейлора и ряды Фурье в нейросетях - youtube
Оптимизация программы обучения - стохастический градиентный спуск - wikipedia
Свёрточные нейронные сети - wikipedia
ну и моя "записная книжка" - в телеграмме
Публично доступные GAN (авторизация аккаунтом гугл):
https://wepik.com/ai-generate
https://stablediffusionweb.com/
Заключение и авторское мнение: критика прогнозов о скорой сингулярности
P.S. не советую верить всяким лицам нетрадиционной ориентации, особенно - в части их прогнозов на скорейшее пришествие искусственного сверх-интеллекта и прочих "сингулярностей" - на сегодняшний день это просто смехотворно. Сэм Альтман выдавливает все соки из своего "хайпа", со временем всё больше напоминая эдакую Грету Тундберг в мире нейросетей. Туда же - всех нытиков, кто сетует на нейросети "лишающие" их работы.
Есть лишь один способ угомонить этих "недо-эко-активистов" и остальных плоскоземельщиков - игнорировать их и деликатно презирать всех кто ещё не делает этого. От всей души прошу. Просвещения и всех благ дочитавшим.
Комментарии (0)
Войдите или зарегистрируйтесь, чтобы оставить комментарий
Загрузка комментариев…