
Введение: основы нейронных сетей для новичков
Сегодня мы разберём самые базовые понятия нейронных сетей, познакомимся с первой архитектурой и постараемся понять, что скрывается внутри этой, на первый взгляд, волшебной коробки. Если вы только начинаете путь в машинном обучении — эта часть статьи для вас.
История нейронных сетей: от первых компьютеров до персептрона
Как известно, первые компьютеры изначально создавались для математических расчётов и военных задач. В 1942 году появился аппарат, отдалённо напоминающий современные «железные кони».
В конце 1950-х годов был представлен первый прототип нейронной сети — персептрон. С тех пор развитие нейросетей шло дальше: учёные ввели ключевые идеи, такие как алгоритм оптимизации обратного распространения ошибки и разнообразные функции активации, без которых трудно представить современное машинное обучение.
Почему его называют «искусственным интеллектом»: понятие ИИ и отличия от биологического интеллекта
Название «искусственный интеллект» отражает идею моделирования явлений, похожих на интеллект человека, с помощью математических моделей. Разумеется, в нашем мозгу нет явных операций, похожих на матричные умножения и градиенты, но концептуально работа нейронных сетей вдохновлена связями между нейронами.
Обучение ИИ часто сравнивают с обучением ребёнка. Сначала малыш ничего не понимает, затем получает поток наблюдений и объяснений. Родители показывают: большие объекты с зелёной «шевелюрой» — это деревья, а животное, которое говорит «мяу», — это кот.
Если ребёнок ошибочно назовёт яблоко грушей, окружающие поправят его: «Это не груша, это яблоко». Повторение таких корректировок помогает ребёнку снижать ошибки. Машины обучаются схожим образом: вместо родителей — данные и алгоритмы, а вместо прямого наставления — функции потерь и оптимизаторы.
Персептрон — архитектура первой нейронной сети
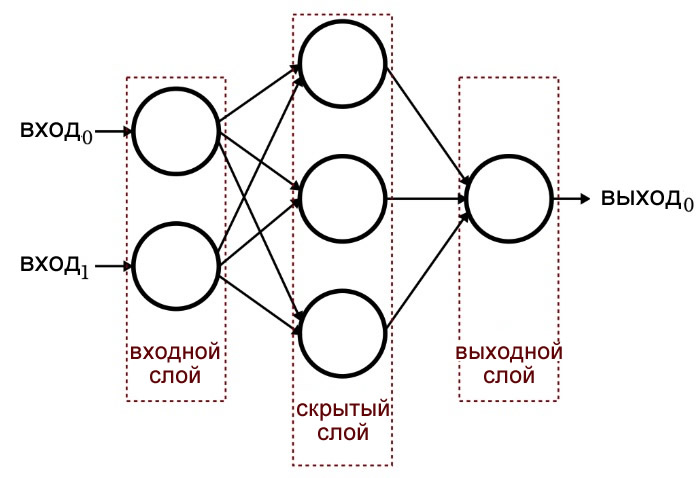
Знакомьтесь — персептрон. Это «дедушка» среди нейронных сетей, и несмотря на простоту, персептрон до сих пор полезен для объяснения базовых принципов. Разберём его по частям, чтобы понять, как он работает.
Слои и нейроны в персептроне: входной, скрытые и выходной слои
Начнём с понятия нейрона (его также называют узлом). Нейрон — это «кружок» на схеме, в котором происходят вычисления. Входные и выходные нейроны выполняют специфичную роль, но базовая идея одна: в нейроне происходят операции над поступающими значениями.
Нейроны, расположенные вертикально друг под другом, образуют слой. В классическом персептроне можно выделить три типа слоёв:
Входной слой — сюда поступают исходные данные. В типичной схеме персептрона входной слой представлен одной колонкой нейронов и часто называется «нулевым слоем».
Скрытый слой — часть сети, недоступная пользователю напрямую, где происходят основные вычисления. Скрытых слоёв может быть один или несколько, в каждом — любое количество нейронов.
Выходной слой — слой, где формируется результат после всех вычислений. Обычно также представлен одной колонкой нейронов.
Следует отметить, что входной слой не имеет весов и смещений — это просто место, куда подаются значения; реальные вычисления начинаются со скрытых слоёв.
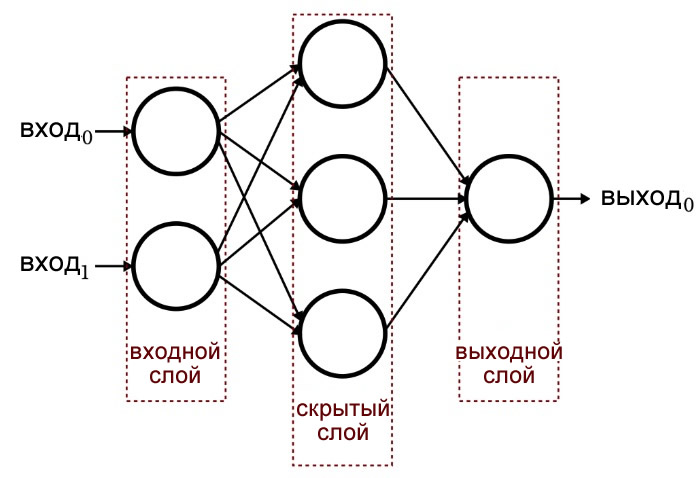
Пример персептрона со скрытым слоем, состоящим из двух колонок нейронов.
Веса и смещения (weights и bias): как нейрон «решает», что важно
Нейроны — пока что чёрные ящики, в которых выполняются операции. Чтобы понять, какое входное значение важнее, вводятся веса.
Вес (weight) — это число, на которое умножается входное значение; обычно веса обозначаются буквой w.
Если на вход поступает значение ноль, нейрон может «не сработать», поэтому используют смещение — небольшое число, добавляемое к сумме произведений входов на веса. Смещения обозначаются буквой b.
Вместе веса и смещения позволяют нейрону генерировать ненулевой отклик и смещать порог активации, делая модель гибкой.
Инициализация и подбор весов и смещений: случайная и оптимизация
Как подбирают веса и смещения? Непосредственно перед обучением они обычно инициализируются случайно. Далее алгоритмы оптимизации (например, стохастический градиентный спуск с обратным распространением ошибки) корректируют эти параметры на основе функции потерь. Процесс подборки — это не ручная настройка, а автоматическая оптимизация.
Вычисления в сети: пример вычисления для одного нейрона
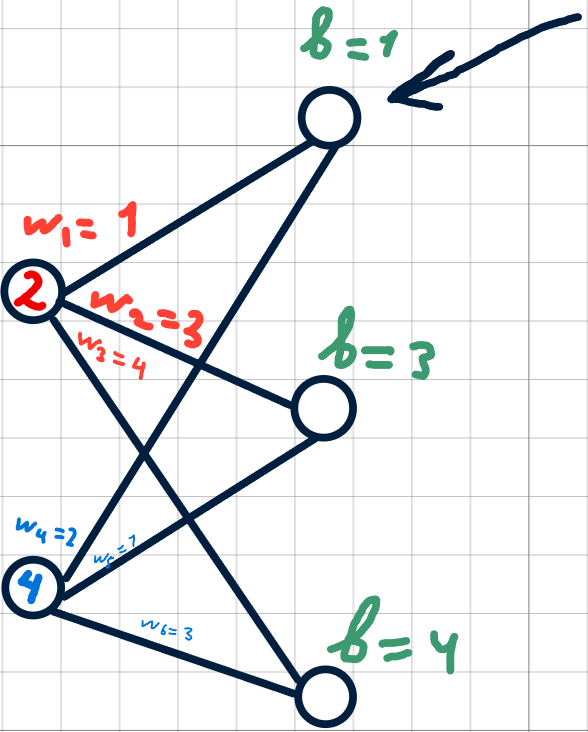
Предположим, веса и смещения случайно инициализированы. Посчитаем значение одного нейрона первого скрытого слоя.
Необходимо умножить значение первого входного нейрона на соответствующий вес, прибавить произведение второго входного нейрона на его вес и добавить смещение. Проще это видеть на картинке:
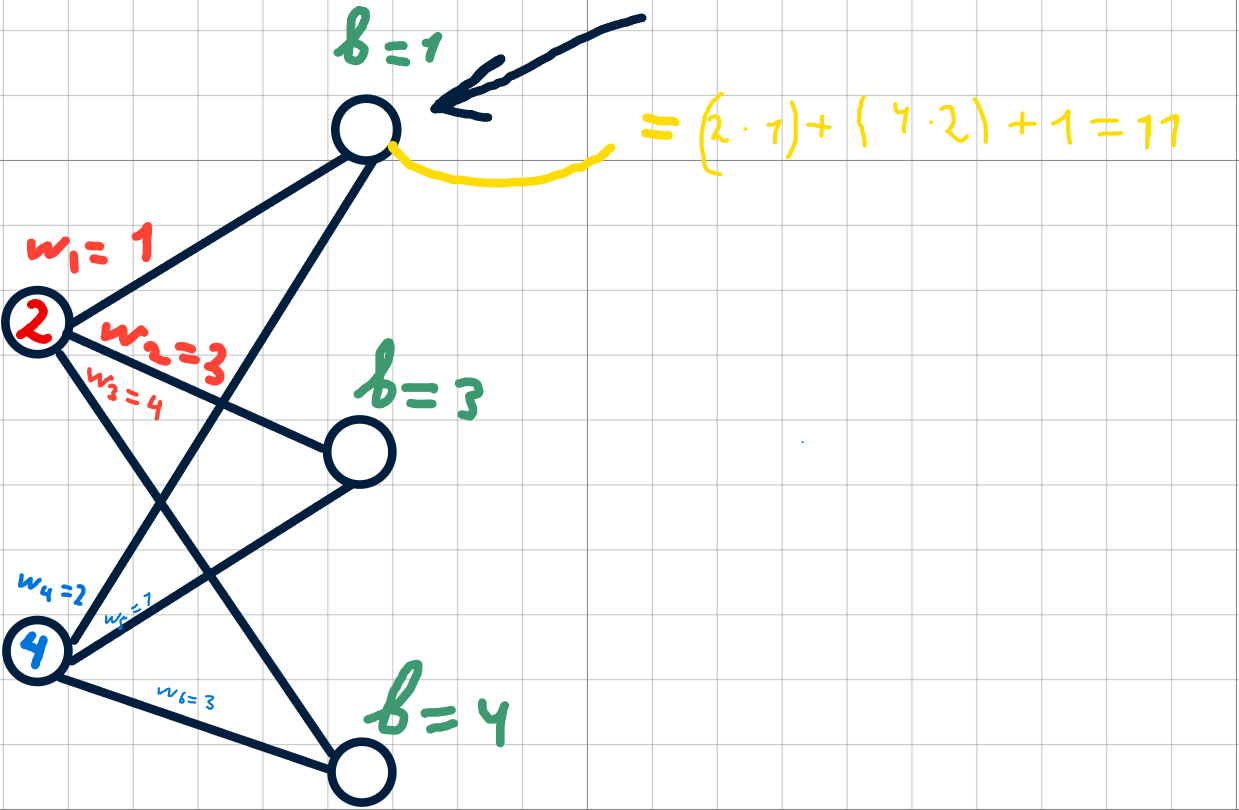
Аналогично вычисляются значения остальных нейронов скрытого слоя по соответствующим весам и смещениям.
Вычисления в скрытом слое: линейная алгебра и матричные операции
Почему считать каждый нейрон по отдельности? Это долго и неэффективно. Вместо этого удобно использовать линейную алгебру: представить входные значения в виде вектора и веса — в виде матрицы.
Вектор входных значений можно обозначить как x, а матрицу весов первого слоя — как W1. Вектор смещений — b1.
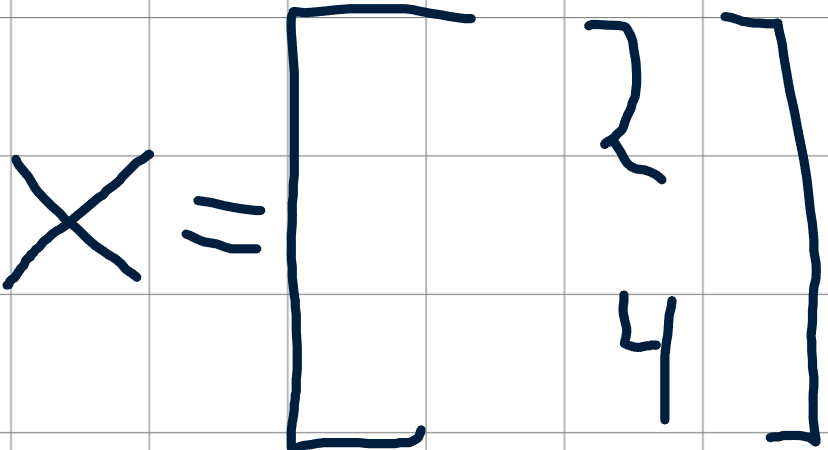
Матрица весов для первого слоя (пример 2x3):
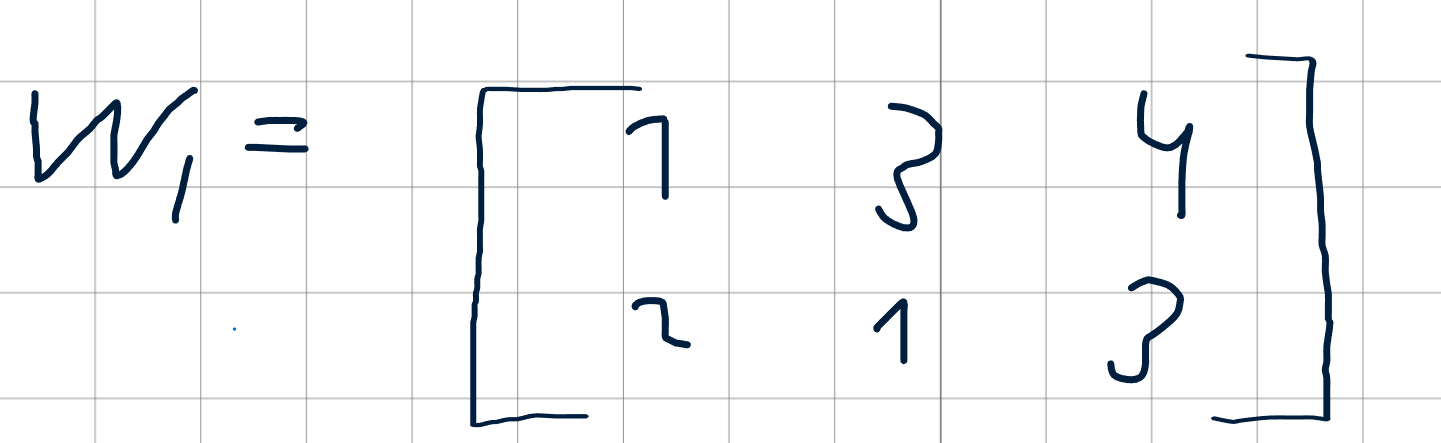
Вектор смещений:
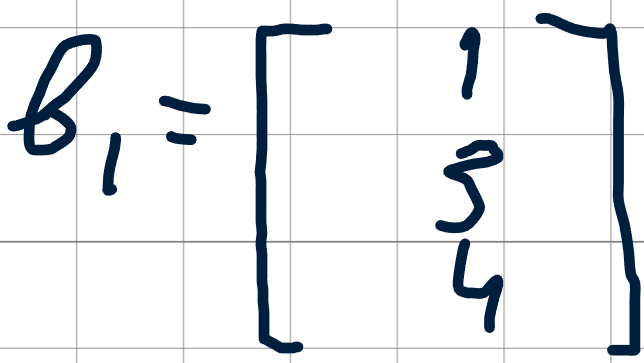
Тогда вычисление выходов скрытого слоя сводится к матричной операции:
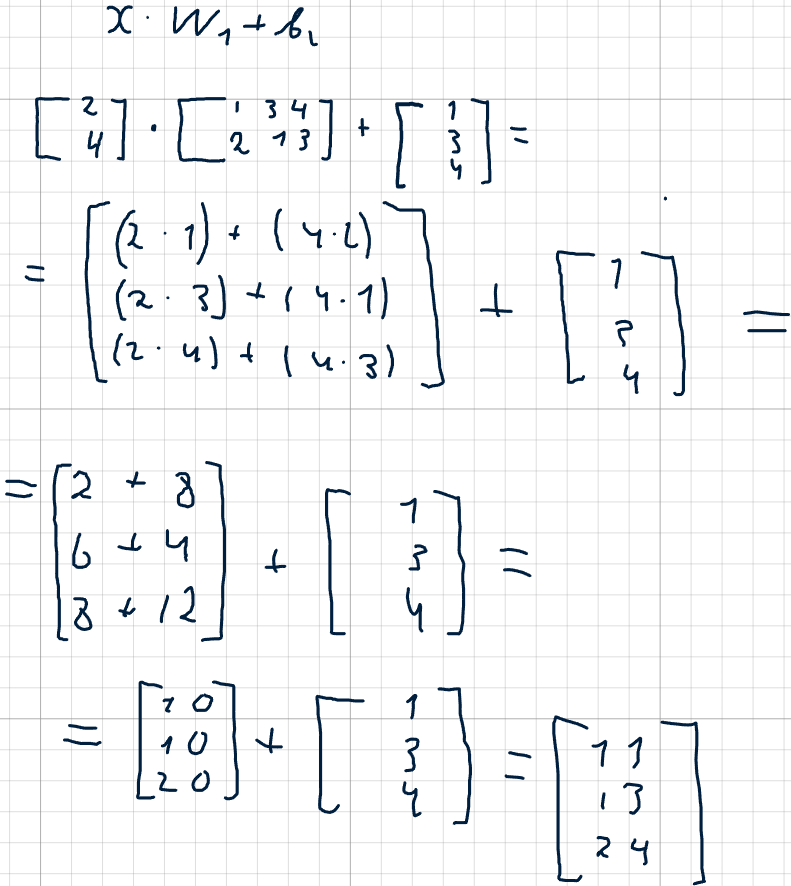
Результат совпадает с тем, что бы мы получили, считая по очереди для каждого нейрона, но матричный подход значительно эффективнее и удобнее при программной реализации.
Функция активации: зачем нужна, ReLU и важность нелинейности
После линейной комбинации входов и весов нам нужно преобразовать полученное значение в определённый диапазон — это делает функция активации. Выбор диапазона и типа функции зависит от задачи.
Например, в бинарной классификации (решение «да/нет», например, выдавать ли кредит) часто используют диапазон от 0 до 1, чтобы интерпретировать выход как вероятность.
Число на выходе функции активации отражает «активность» нейрона: чем больше значение, тем сильнее нейрон «сработал».
Одна из самых простых и популярных функций активации — ReLU (Rectified Linear Unit).

Говоря простым языком:
Если вход нейрона x <= 0, ReLU возвращает 0.
Если вход положителен, ReLU возвращает то же положительное число.
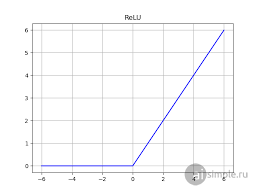
График функции ReLU
Ключевое свойство функции активации — нелинейность. Без нелинейных функций активации сеть сводится к последовательности линейных преобразований и не сможет решать сложные нелинейные задачи.
Выбор функции активации зависит от задачи: существуют разные функции (sigmoid, tanh, ReLU, Leaky ReLU и др.), каждая имеет свои плюсы и минусы.
Функция потерь (loss): как оценить качество сети, пример MSE
На начальном этапе сеть, естественно, будет допускать ошибки. Чтобы количественно оценивать качество предсказаний, используют функцию потерь (loss function). Она возвращает число — чем выше значение, тем хуже предсказания модели.
В этой статье в качестве примера используется среднеквадратичная ошибка — MSE (Mean Squared Error).

Где:
n — количество примеров;
y_true — истинные значения;
y_pred — предсказания модели.
Покажем работу MSE на простом примере:
y_true | y_pred |
3 | 2.8 |
5 | 5.1 |
7 | 2 |
Шаг 1. Разница между истинными значениями и предсказанием:



Шаг 2. Возводим ошибки в квадрат:



Шаг 3. Сумма квадратов ошибок:

Шаг 4. Деление на количество примеров:

Полученный числовой результат интерпретируется в зависимости от задачи: в некоторых случаях меньшая MSE однозначно лучше, в других — используются специфичные критерии. Основная цель — оптимизация функции потерь, обычно с помощью обратного распространения ошибки и градиентных алгоритмов.
Прямое распространение (forward propagation) на Python — введение
Теперь мы готовы объединить все знания и реализовать прямое распространение в коде на Python. Так как реализация может быть достаточно длинной, в дальнейшем я буду оставлять подробные комментарии в коде, объясняющие каждую операцию.
Генерация случайных данных в Python — numpy для случайных значений
ии в коде только в случае острой необходимости.
Мы возьмем случайные данные и случайные значения.
Импорт библиотеки numpy в Python для создания случайных массивов (random, numpy)
import numpy as npX = np.array([[0.1, 0.5]])
y_true = np.array([[0.7]])
w1 = np.array([[0.2, 0.4], # Вес для нейрона 1 скрытого слоя
[0.3, 0.1]]) # Вес для нейрона 2 скрытого слоя
b1 = np.array([0.1, 0.2]) # Смещение для скрытого слоя
w2 = np.array([0.5, -0.2]) # Вес для выходного нейрона
b2 = np.array([0.3]) # Смещение для выходного слоя
def relu(x):
return np.maximum(0, x)
def mse_loss(y_true, y_pred):
return np.mean((y_true - y_pred) ** 2)
# 1. Проходим через скрытый слой
z1 = np.dot(X, w1) + b1
a1 = relu(z1)
# 2. Проходим через выходной слой
z2 = np.dot(a1, w2) + b2
y_pred = z2
# 3. Вычисление ошибки (MSE)
loss = mse_loss(y_true, y_pred)
print("Предсказание:", y_pred)
print("Ошибка (MSE):", loss)Что такое прямое распространение нейронной сети (forward propagation)?
Что же такое прямое распространение? Это процесс, при котором мы "прогоняем" данные через нейронную сеть, начиная с входного слоя и заканчивая выходным. В ходе этого процесса входные значения умножаются на веса, суммируются со смещениями и проходят через функции активации — всё это приводит к получению предсказания сети.
Заключение: выводы по прямому распространению и следующие шаги по обучению нейросети
Мы прошлись от самых основ архитектуры персептрона и написали код на Python, который реализует прямое распространение. Надеюсь, мне удалось донести до новичков, что работа нейронной сети — это не волшебство, а результат применения математики.
Конечно, пока наша нейронная сеть ещё не идеально работает, и у нас есть куда расти. В следующих статьях мы будем обучать её и дорабатывать, рассматривая алгоритмы оптимизации, обратное распространение ошибки (backpropagation), подбор гиперпараметров и практические приёмы повышения качества модели.
Комментарии (0)
Войдите или зарегистрируйтесь, чтобы оставить комментарий
Загрузка комментариев…